Collaboration
Back in high school, I built robots with a group of exactly the sort of teenagers you’d expect to find in a robotics club. I was physically weaker than most of my peers, so I had to use tools and leverage to complete routine tasks that others could do with their bare hands. This gave me more practice with those tools than others were getting. When the tasks scaled up in difficulty – a stuck bolt turning out to be very stuck, a thicker sheet of metal turning out to be unusually reluctant to bend – my tool use tended to scale up quickly thanks to my constant practice with it, whereas peers who’d been brute forcing the task before would face the initial learning curve of the tool at that moment.
I think I’m doing a similar thing with collaboration. I have to try really hard to keep in touch with people because my default state includes mostly avoiding everyone. But by trying on purpose, I seem to have accidentally developed systems which scale better than the innate strengths which many take for granted in themselves.
And I’m writing about trying on purpose, weird though it feels, because several people have recently remarked on the quality of my collaboration. What they perceive as collaborativeness, I experience as a desire to work with my friends, and a recognition that the most effective way to do this is to make friends among my colleagues.
Assorted Git & Unix Tips
In my present role, I get to work with colleagues of delightfully diverse skill sets. Sometimes I’m learning directly from experts, and other times I get to learn by teaching in areas where I happen to have the local maximum of experience. One delightful colleague has a coding bootcamp background which rapidly exposed them to a lot of important topics, and I find myself helping to fill in the gaps where a couple hours of instruction don’t quite get the point across like years of practice.
I’m writing this to capture, in no particular order, some advice that I’m noticing myself giving consistently. I can only guess at how I accumulated it, and I cannot promise that there won’t be exceptions to any of these “rules”. But I suspect someday in the future I’ll be interested in looking back on notes like this, so onto the blog they go!
DIY Shoe Chains
The Pacific Northwest is dangerously frozen at the moment. Other regions handle conditions like this just fine. But a freeze like this is especially dangerous to us because most people are unprepared for it.
Right now we’ve got a bunch of frozen sleet on the ground that looks like snow, but offers the traction of an ice skating rink. This morning I thought I could cross the “snow” in regular shoes, and fell (embarrassingly, but non-injuriously) immediately. I was able to go inside and put on my shoe chains because I keep a pair on hand for occasions like this, and with chains the ice was as easy to walk on as snow would be. But it got me thinking about people who might not have thought ahead to own shoe chains. You can’t just order a pair for use today; nobody’s delivering anything in this weather.
So I did a quick experiment to see whether adequate shoe chains could be assembled out of stuff that a normal person might have on hand. All the commercial ones really are, after all, is a piece of something stretchy and some chain. Image below the fold.
Making Dice
If you’re here for pretty pictures of dice, prepare to be disappointed. Making adequate dice is easy, but taking good photos of them exceeds my current skills.
In today’s standard “how I spent my winter vacation” small talk, I showed some colleagues a dice set that I made last week, and they seemed surprised when I explained that it was relatively easy.
Making excellent or perfect dice is not easy, but I’m not trying for excellent or perfect. I’m trying for “nice to look at” and “capable of showing random-feeling numbers when I roll them”. Those goals are easy to achieve with cheap products from the internet.
..more:
If you want to learn to make good dice, go watch Rybonator on YouTube, and the algorithm will start suggesting other good channels as well.
Next I’m going to share some Amazon links, and a note of the approximate price at time of writing. They aren’t affiliate links because signing up for the affiliate program requires more paperwork than I feel like doing right now. But they are the specific items I’ve been using to get pretty-okay dice out of.
The basic materials you’ll need to make dice are:
- A dice set mold (~$8). Good molds are a solid slab of material. This is not a good mold, but it does make dice.
- Epoxy resin. I got the 16oz of this set (~$9) because it was the cheapest option that seemed adequate, and it was cheap, and it was adequate. When warmed in boiling water before mixing, it has very few bubbles, and it cures overnight if left in a warm place.
- Clean disposable cups and popsicle sticks or equivalent stirrers. Grab these from your recycling or dollar store. ($0-$2)
- Waterproof gloves that you don’t mind getting resin and paint on, if you don’t want high-tech chemicals on your skin.
A dice mold and resin are enough to get you some transparent dice, but that’s boring. You can include household objects like game pieces or beads in the dice, and you can buy additives specifically designed for resin casting:
- Mica powder like this colorful set (~$7) or this metallic set (~$10) gives a shiny metallic or pearlescent look
- Dye like this set (~$10) gives the resin an even, transparent color.
- Glitter like this assortment (~$11) can sparkle like tiny stars, contrast pleasantly with dyed resin, or just display interesting behaviors where the larger pieces sink if the resin is too warm and the smaller pieces remain in suspension.
Plan what you want to include in a given dice set before starting to mix the resin. I find that 40ml (20ml each of resin and hardener) is just right for a single pour of the mold linked above. Then it’s just a matter of following the directions for the resin. After mixing, you can split the resin into several different disposable cups if you’d like to pour different colors together.
Once the dice are hard, unmold them and be amazed! If you want the numbers to be visible, consider flooding them with whatever paint you have on hand, then wiping off the excess with a paper towel. The molds emboss the numbes into the dice, so the number will be the only paint remaining after you wipe it.
If the dice come out too rough, zona papers (~$12) are popular for sanding to a glass-like finish.
If the dice have huge bubbles, you can fix them with UV resin (~$10) and an ultraviolet bulb. The trick to the UV stuff is making sure that the wavelength required by the resin (405-410nm) is included in the spectrum emitted by the lamp (385-410nm). You may already have a UV lamp around if you do gel nails or resin printing.
I find that bubbles often show up in the corners of dice, and sticking some clear tape to the sides I’m mending with UV resin helps keep it where it belongs while letting the light in to harden it. I’ve also gotten some fun effects by painting the inside of the bubble a contrasting color before filling it with UV resin. After repairing bubbles with UV resin, the affected sides often need to be flattened out with a file or coarse sandpaper before polishing with fine sandpaper or zona papers.
In making several sets of increasingly less-bad dice, I’ve noticed that some techniques seem to yield better outcomes:
- Start with the resin really hot. I set both prats of the epoxy in a container of almost boiling water before use, then dry them off and measure it out immediately. Hot resin flows better.
- When using large glitter, make sure to get some glitter-free resin into the very bottom of each die first, or stir it. Big inclusions have a nasty habit of blocking the resin from getting into the tip of the D4.
- Place the mold on a plate or tray before pouring, and do not remove it from the tray until the dice are hard. Bending the mold at all changes the volume of the cavities, which presses resin out then sucks air in.
- Smear some resin on the lid before capping the mold, and slowly roll the lid onto the mold. Setting the lid straight down allows air to be trapped under it in the middle.
- Over-fill the mold cavities slightly.
- Expect heavier inclusions, like large glitter, to sink to the bottom when the resin is poured hot. The pros often wait for the resin to get tacky before pouring part of a die, but that’s advanced technique and I have yet to try much of it.
- Paint can be easily removed from the dice numbers with an ultrasonic cleaner. Don’t try to clean the dice this way if you want the paint to stay in!
This barely scratches the surface of dice-making, and there are better resources on every topic for becoming an expert, making custom molds, and other advanced topics. Although it’s very hard to make excellent dice, it’s shockingly cheap and easy to make mediocre dice, and mediocre dice are often more than adequate to have fun with.
Retroreflectors & Storing Ground Glass
Retroreflectors are fun. I finally got around to picking up some cheap glass blast media today (mine’s the 40/70 grit recycled bottle glass from Harbor Freight / Central Pneumatic) and did some testing with various paints and glues that I had lying around. I’m using it as retroreflective beads. When I hear “beads” I think of things with holes in them for putting on a string, but in this case it means more like beads of condensation – tiny round blobs. They feel gritty like beach sand, and being made from clear glass, they look like unusually sparkly white sand as well.
DIY Thimble
Over the past couple weeks, my schedule has had a higher than usual concentration of the kind of meetings where one sits off-camera and listens to a presenter talk. Like many engineers who knit in meetings, I find that keeping my hands busy helps me focus. Knitting puts me on the losing side of a battle between “don’t drop any stitches” and the laws of physics, however, so instead I’ve been hand sewing quite a bit.
Lumenator
About a year ago, I found out about lumenators. The theory is that if you put sunshine-ish amounts of light onto a creature, the creature reacts as it would in sunlight.
So, I built one. It’s technically brighter than the sun.
Playing Dress-Up With Starlink
Some friends showed me a post investigating whether Starlink dishes still work when decorated in various ways. They asked whether I was able to reproduce the results. So I pulled the dish down off my roof and tested it with a few things that I had lying around the house and yard.
Methodology Notes:
I gathered data in my camera roll: a snapshot of the setup, followed by a screencap of the “router <-> internet” pane of the speedtest within the Starlink Android app. I left the dish set up in the same spot, which was at ground level but reported no obstructions when I did the sky scan thing in the app. I power cycled the dish once during the experiment, roughly halfway through the control tests for the “is it slower?” question, because I needed to plug something else into the extension cord that it was using for a minute.
I’m located south of the 45th parallel.
Will It Send?

For my first batch of tests, I was curious whether I could get any data in and out via Starlink with various configurations of stuff on and around the dish. I only ran one speedtest each for these.
I started by suspending things over Starlink, because I knew some of the materials would get heavy (such as wet cotton cloth) and I was scared of hurting the little motors inside that it uses to move itself around. I draped a canvas tarp over the north side of a fence to make an impromptu photo studio for the dish. The dish had an unobstructed view of the sky upward and to the north. I placed metal folding chairs to the east and west of the dish, with their backs closest to the dish, to hold up the various covers. I used some old brake pads to weigh down the things that I draped over the chairs so they wouldn’t blow away.
- No cover, control to make sure Starlink works in this position. It sends. 146 Mbps down, 15 Mbps up.
- Covered with clear-ish greenhouse plastic. It sends. 148 Mbps down, 15 Mbps up.
- Same as (2) but with a cotton bedspread over the plastic. It sends. 170 Mbps down, 8 Mbps up.
- Same as (3) but with the bedspread soaking wet. It does not send. The app reports “offline, obstructed”.
- Plastic from (2) plus a single layer of corrugated cardboard box. It sends. 62 Mbps down, 9 Mbps up.
- Same as (5) but I dumped some water on the box. It mostly ran off. It sends. 65 Mbps down, 9 Mbps up.
- Double layer of row cover, like you put on plants in the garden to keep the frost from hurting them. It sends. 94 Mbps down, 11 Mbps up.
- Single layer of ratty old woven plastic tarp. It sends. 109 Mbps down, 6 Mbps up.
For the final 2 tests, I got a bit braver about putting things directly on the dish, instead of just suspending them above it.
- Dish in a black plastic trash bag like you’re throwing it out. It sends. 147 Mbps down, 10 Mbps up.
- Same tarp as from (8), but directly on the dish instead of hanging above it. It sends. 207 Mbps down, 20 Mbps up.
Is It Slower?
As you’ll notice in the numbers that I was getting in the above trials, sometimes covering the dish yields a faster single speed test than having it exposed. That seems wrong. I suspect that this is normal variance based on what satellites are available, but I don’t actually know what behavior is normal. So I did a few more tests in configuration 10, and a bunch of tests in configuration 1, to make sure we’re not in a timeline where obstructing a radio link somehow makes it perform better.
| Mbps Down | Mbps Up |
|---|---|
| 207 | 20 |
| 173 | 5 |
| 138 | 11 |
| 124 | 13 |
| 180 | 19 |
| 101 | 9 |
| Mbps Down | Mbps Up |
|---|---|
| 104 | 24 |
| 114 | 4 |
| 119 | 10 |
| 100 | 16 |
| 111 | 14 |
| 147 | 5 |
| 147 | 5 |
| 97 | 15 |
| 218 | 15 |
| 87 | 15 |
| 176 | 16 |
| 192 | 6 |
| 125 | 6 |
I left it all out overnight, and the canvas tarp that I’d been using as a visual backdrop blew off of the fence so it was covering the dish. I made a video call on the connection with the canvas over the dish and didn’t notice any subjective degradation of service compared to what I’m accustomed to getting from it.
Conclusions
Starlink definitely still works when I put dry textiles between the dish and the satellite. It doesn’t seem to matter if the textiles are directly on the dish or suspended a couple feet above it.
I’m surprised that Eric Kuhnke’s Starlink worked with 2 layers of wet bedsheet over it. The only case in which I managed to cause my Starlink to report itself as being obstructed was when I had a wet bedspread suspended in the air over it. I don’t really want to start piling wet cloth directly on the dish, though, because wet cloth is heavy and I’m scared of overloading the actuators.
Starlink gets kind of warm during normal operation, as demonstrated by the cats. I wouldn’t want to leave mine in a dark colored trash bag or under a dark colored tarp on a sunny day in case it overheated. And there’s no need to – if you don’t want people to know you’re using one, you can just suspend an opaque and waterproof tarp above it and there’ll be better airflow around the dish itself and thus less risk of overheating.
Have fun!
tree-style tab setup
How to get rid of the top bar in firefox after installing tree style tab:
In about:config (accept the risk), search toolkit.legacyUserProfileCustomizations.stylesheets and hit the funny looking button to toggle it to true.
In about:support, above the fold in the “Application Basics” section, find Profile Directory.
In that directory, mkdir chrome, then create userChrome.css, containing:
#main-window[tabsintitlebar="true"]:not([extradragspace="true"]) #TabsToolbar
{
opacity: 0;
pointer-events: none;
}
#main-window:not([tabsintitlebar="true"]) #TabsToolbar {
visibility: collapse !important;
}
top/htop in windows is ctrl+shift+esc
Helping a neighbor with a windows update issue today, I explained that asking a Linux admin to use Windows is like asking a Latin speaker to translate a document from Spanish. Most of the concepts are similar enough that they’ll be more helpful than a monolingual English speaker, but good guessing is not the same as fluency.
Since it was a problem with good directions on how to fix it, the process mostly went smoothly. As I complained to a Windows admin friend afterwards, it was fine except all the slashes in paths were backwards, and I couldn’t find the command prompt equivalent to Linux’s top or htop.
My Windows friend pointed out the obvious solution to me: The windows equivalent to top is not a command at all, but rather the task manager GUI. Next time I need top or htop in Windows, I’ll try to remember to hit ctrl+shift+esc to summon that interface instead.
And next time I’m searching the web for “windows command prompt top” “windows equivalent of top command”, and other queries that assume it’ll let me live in the terminal like my preferred operating systems, I might just end up back on this very post. Hi, future me!
transcription with mplayer and i3
I recently wanted to manually transcribe an audio recording. I prefer to type into LibreOffice Writer for this purpose. Writer has an audio player plugin for transcription, but unfortunately its keyboard shortcuts didn’t work when I tried it.
I just want to play some audio in one workspace and have play/pause and 5-second rewind shortcuts work even when another window is focused.
Since I am using i3wm on Ubuntu, I can glue up a serviceable transcription setup from stuff that’s already lying around.
The first challenge is to persuade an audio player to accept commands while it’s not the window in focus. By complaining about this problem to someone more knowledgeable than myself, I learned about mplayer’s slave mode. From its docs, I learn that I can instruct mplayer to take arbitrary commands on a fifo as follows:
$ mkfifo /tmp/mplayerfifo
$ mplayer -slave -input file=/tmp/mplayerfifo audio-to-transcribe.mp3
Now I can test whether mplayer is listening on the fifo. And indeed, the audio pauses when I tell it:
$ echo pause > /tmp/mplayerfifo
At this time I also test the incantation to rewind the audio by 5 seconds:
$ echo seek -5 > /tmp/mplayerfifo
Since both commands work as expected, I can now create keyboard shortcuts for them in .i3/config:
bindsym $mod+space exec "echo pause > /tmp/mplayerfifo"
bindsym $mod+z exec "echo seek -5 > /tmp/mplayerfifo"
After writing the config, $mod+shift+c reloads it so i3 knows about the new shortcuts.
Finally, I’ll make sure this keeps working after I reboot. I’ll make an alias in my ~/.bashrc to save having to remember the mplayer incantation:
$ echo "alias transcribe='mplayer -slave -input file=/tmp/mplayerfifo" >> ~/.bashrc
And to automatically create the fifo once on boot:
$ echo "mkfifo /tmp/mplayerfifo" >> ~/.profile
Now after I source ~/.bashrc, I can play media with this transcribe alias, and the keyboard shortcuts control it from anywhere in my window manager.
irssi and libera.chat
I’m in some channels that are moving from Freenode to Libera.
My irssi runs on a DigitalOcean droplet, and whenever I try to connect to Libera from that instance, I get the error:
[libera] !tungsten.libera.chat *** Notice -- You need to identify via SASL to use this server
Libera’s irssi guide (https://libera.chat/guides/irssi) says how to connect with SASL, and down in their sasl docs (https://libera.chat/guides/sasl) they mention that SASL is required for IP ranges that are easy to run bots on... including my VPS.
The fix is to pop open an IRC client locally (or use web IRC), connect to Libera without SASL, and register one’s nick and password. After verifying one’s email address over the regular connection, the network can be reached via SASL from anywhere using the registered nick as the username and the nickserv password as the password.
Obvious in retrospect, but poorly SEO’d for how the problem looks at the outset, so that’s how I worked around problems reaching Libera from Irssi on a VPS.
Assembly Lines
This time last year, my living room was occupied by a cotton mask production facility of my own devising. I had reverse engineered a leftover surgical mask to get the approximate dimensions, consulted pictures of actual surgeons’ masks, and contrived a mask design which was easy-enough to sew in bulk, durable-enough to wash with one’s linens, and wearable-enough to fit most faces.
Tinkering with and improving the production line was delightful enough to make me wonder if I’d missed a deeper calling when I chose not to pursue industrial engineering as a career, but the actual work – the parts where I used myself as jsut another machine to make more masks happen – was profoundly miserable. At the time, it made more sense to attribute that misery to current events: The world as we knew it is ending, of course I’m grumpy. I took it for granted that the sewing project of making masks was equivalent to the design/prototype/build cycle of my more creative sewing endeavors, and assumed that it was supposed to be equally enjoyable.
A year later, however, I’m running a similar personal assembly line on an electrical project, and noticing some patterns. I have to do 4 steps each on 96 little widgets to complete this phase of the project. My engineering intuition says that the optimal process would be to do all of step 1, then all of step 2, then all of step 3, then all of step 4. That seems like it should be the fastest, and make me happy becuase it’s the best – no wasted effort taking out then putting away the set of tools for each step several times.
The large-batch process would also yield consistency across all of its outputs, so that no one widget comes out much worse than any other. Consistency is aesthetic and satisfying in the end result, so the process which yields consistency should feel preferable... but instead, it feels deeply distasteful to stick with any one production phase for too long. What’s going on there? What assumption is one side of the internal argument using that the other side lacks?
It took me 2 steps over about 24 of the widgets to figure out what felt so wrong about that assembly-line reasoning: The claims of “best” and “fastest” only hold if the process being done remains exactly the same on widget 96 as it was on widget 1. That’s true if a machine is doing it, but false if the worker is able and allowed to think about the process they’re working on. Larger batch sizes are optimal if the assembly process is unchanging, but detrimental if the process needs to be modified for efficiency or ease of use along the way. For instance, I’d initially planned a design that needed about 36’ of wire, but by examining and contemplating the project when it was ready to be wired up, I found a way to accomplish the same goals with only about 23’ of wire. If I’d been “perfectly efficient” in treating the initial design as perfect, I would likely have cut the wire into the lengths that were needed for the 36’ plan before the 23’ design occurred to me, and that premature optimization would have destroyed the materials I’d need to assemble the more efficient design once I figured it out.
In other words, a self-modifying assembly line necessarily shrinks the batch size that it’s worth producing. I’ve seen the same thing in software – when automating a process, it’s best to do it by hand a couple times, and then test a script on a small batch of input and fix any errors, and then apply it to larger and larger batches as it gets closer and closer to the best I can get it. It’s just easier to notice the phenomenon in a process that uses the hands while leaving the brain mostly free than in processes of more intellectual labor.
And there was the answer as to why attempting to do all 96 of step 1, then all 96 of step 2, felt terrible: Because using the maximum batch size implied that the process was as good as I’d be able to get it, and that any improvements I might think of while working would be wasted if they weren’t backwards-compatible with the steps of the old process that were already completed. Smaller batch sizes, then, have an element of hope to them: There will be a “next time” of the whole process, so thinking about “how I’d do it next time” has a chance to pay off.
pulseaudio & volumio
The speakers in my living room are hooked up to a raspberry pi that runs Volumio. It’s a nice way to play music from various sources without having to physically reconfigure the speakers between inputs.
Volumio as a pulseaudio output
For awhile, my laptop was able to treat Volumio as just another output device, based on the following setup:
- the package pulseaudio-module-zeroconf was installed on the pi and on every laptop that wants to output audio through the living room speakers
- the lines load-module module-zeroconf-publish and load-module module-native-protocol-tcp were added to /etc/pulseaudio/default.pa on the pi
- the line load-module module-zeroconf-discover was added to /etc/pulse/default.pa on my Ubuntu laptop
- pulseaudio was restarted on both devices after these changes (pulseaudio -k to kill, pulseaudio to start it)
starting pulseaudio on boot on Volumio
And then as long as the laptop was connected to the same wifi network as the pi, it Just Worked. Until, in the course of troubleshooting an issue that turned out to involve the laptop having chosen the wrong wifi, I power cycled the pi and it stopped working, because pulseaudio was not yet configured to start on boot.
The solution was to add the following to /etc/systemd/system/pulseaudio.service on the pi:
[Unit]
Description=PulseAudio system server
[Service]
Type=notify
Exec=pulseaudio --daemonize=no --system --realtime --log-target=journal
User=volumio
ExecStart=/usr/bin/pulseaudio
[Install]
And then enabling, starting, and troubleshooting any failures to start:
systemctl --system enable pulseaudio.service
systemctl --system start pulseaudio.service
systemctl status pulseaudio.service -l # explain what went wrong
systemctl daemon-reload # run after editing the .service file
Thanks to Rudd-O’s blog post, which got me 90% of the way to the “start pulseaudio on boot” solution. Apparently systemctl started caring more about having an ExecStart directive since that post was written, which meant I had to inspect the resulting errors, which means I’m writing down the resulting tidbit of knowledge so that I can find it again later.
future work
Nobody in my household has yet found a good way to persuade the Windows computer who lives under the TV to speak pulseaudio yet. If I ever figure that out, I’ll update here.
Moving on from Mozilla
Today – Friday, May 22nd, 2020 – is within days of my 5-year anniversary with Mozilla, and it’s also my last day there for a while. Working at Mozilla has been an amazing experience, and I’d recommend it to anyone.
There are some things that Mozilla does extremely well, and I’m excited to spread those patterns to other parts of the industry. And there are areas where Mozilla has room for improvement, where I’d like to see how others address those challenges and maybe even bring back what I learn to Moz someday.
Why go?
When I try to predict what my 2025 or 2030 self will wish I’d done with my career around now, I anticipate that I’ll want access to opportunities which build on a background of technical leadership and mentoring junior engineers.
It wouldn’t be impossible to create these opportunities within Mozilla, but from talking with trusted mentors both inside and outside the company, I’ve concluded that I would get a lot more impact for the same effort if I was working within a growing organization.
As a mature organization, Mozilla’s internal leadership needs are very different from those of a younger and more actively growing company. There’s a far higher bar at Moz for what it takes to be the best person for a task, because the saturation of “best people” is quite high and the prevalence of entirely new tasks is relatively low in comparison. Technical leadership here seems to often require creating a need as well as filling it. At a growing organization, on the other hand, the types and availabilities of such opportunities are very different.
I’m especially looking forward to leveling up on a different stack in my next role, to improve my understanding of the nuances of the underlying problems our technolgies address. I think it’s a bit like learning a second language: only through comparing and contrasting multiple solutions to the same sort of problem can one understand what traits corrolate to all those solutions’ strengths versus which details are simply incidental.
Why now?
I’ll be the first to admit that May 2020 is a really strange time to be changing jobs. But I have an annual tradition of interviewing at several places, learning what their stacks and cultures and unique fractals of tech debt look like, and then turning down an offer or two because changing roles would be a step backwards for both my career development and overall quality of life.
Shortly before the global conference circuit ground to a halt along with everything else, I started interviewing from a DevOps Advocate position, just to explore what it might look like to turn my teaching hobby into a day job. By the time those interviews were complete, the tech evangelism space had been turned inside out and was rapidly reinventing itself, and the skills that qualified me for the old world of devrel were looking less and less like the kind of expertise that might be needed to succeed in the new one. However, a SRE from the technical interviews suggested that I interview for her team, and upon taking that advice I discovered an organization that keeps most of the stuff I loved about Mozilla while also offering the other opportunities that I was looking for.
As with anywhere, there are a few aspects of my new role that I suspect may not be as great yet as where I’m leaving, but these areas of improvement look like things that I’ll be able to have some influence over. Or at least there’ll be room to push the Overton Window in a good direction!
Want more details on the new role? I’ll be writing more about it after I start on June 1st!
Offboarding
Turns out that 5 years at a place gets you a bit of a pile of digital detritus. Future me might want notes on what-all steps I took to remove myself from everything, so here goes:
- GitHub: Clicking the “pull requests” thing in that bar at the top gives a list of all open PRs created by me. I closed out everything work-related, by either finishing or wontfix-ing it. Additionally, I looked through the list of organizations in the sidebar of my account and kicked myself out of owner permissions that I no longer need. Since my GitHub workflow at Mozilla included a separate account for holding admin perms on some organizations, I revoked all of that account’s permissions and then deleted it.
- Google Drive: (because moving documents around through the Google Docs interface is either prohibitively difficult or just impossible) I moved all notes docs that anyone might ever want again into a shared team folder.
- Bugzilla: The “my dashboard” link at the top, when logged in, lists all needinfos and open assigned bugs. I went through all of these and removed the needinfos from closed bugs, changed the needinfos to appropriate people on open bugs, and reassigned assigned bugs to the people who are taking over my old projects. When reassigning, I linked the appropriate notes documents in the bugs and filled in any contextual information that they didn’t capture. I also checked that my Bugzilla admin had removed all settings to auto-assign me bugs in certain components.
- Email deletion prep: I searched for my old work email address in my password manager to find all accounts that were using it. I deleted these accounts or switched them to a personal address, as necessary. It turned out that the only thing I needed to switch over was my Firefox account, which I initially set up to test a feature on a service I supported, but then found very useful.
- Git repos: When purging pull requests and bugs, I pushed my latest work from actively developed branches, so that no work will be lost when I wipe my laptop
- Assorted other perms: Some developers had granted me access to a repo of secrets, so I contacted them to get that access revoked.
- Sharing contact info: I didn’t send an email to the all-company list, but I did email my contact info to my teammates and other colleagues with whom I’d like to keep in touch.
- Take notes on points of contact. While I still have access to internal wikis, I note the email addresses of anyone I may need to contact if there are problems with my offboarding after my LDAP is decommissioned.
- Wipe the laptop: That’s next. All the repos of Secret Secrets are encrypted on its disk and I’ll lose the ability to access an essential share of the decryption key when my LDAP account goes away, but it’s still best practices to wipe hardware before returning it. So I’ll power it off, boot it from a liveUSB, and then run a few different tools to wipe and overwrite the disk.
Git: moving a module into a monorepo
My team has a repo where we keep all our terraform modules, but we had a separate module off in its own repo for reasons that are no longer relevant.
Let’s call the modules repo git@github.com:our-org/our-modules.git. The module moving into it, let’s call it git@github.com:our-org/postgres-module.git, because it’s a postgres module.
First, clone both repos.:
git clone git@github.com:our-org/our-modules.git
git clone git@github.com:our-org/postgres-module.git
I can’t just add postgres-module as a remote to our-modules and pull from it, because I need the files to end up in a subdirectory of our-modules. Instead, I have to make a commit to postgres-module that puts its files in exactly the place that I want them to land in our-modules. If I didn’t, the README.md files from both repos would hit a merge conflict.
So, here’s how to make that one last commit:
cd postgres-module
mkdir postgres
git mv *.tf postgres/
git mv *.md postgres/
git commit -m "postgres: prepare for move to modules repo"
cd ..
Notice that I don’t push that commit anywhere. It just sits on my filesystem, because I’ll pull from that part of my filesystem instead of across the network to get the repo’s changes into the modules repo:
cd our-modules
git remote add pg ../postgres-module/
git pull pg master --allow-unrelated-histories
git remote rm pg
cd ..
At this point, I have all the files and their history from the postgres module in the postgres directory of the our-modules repo. I can then follow the usual process to PR these changes to the our-modules remote:
cd our-modules
git checkout -b import-pg-module
git push origin import-pg-module
firefox https://github.com/our-org/our-modules/pull/new/import-pg-module
We eventually ended up to skip importing the history on this module, but figuring out how to do it properly was still an educational exercise.
Finding a lost Minecraft base
I happen to administer a tiny, mostly-vanilla Minecraft server. The other day, I was playing there with some friends at a location out in the middle of nowhere. I slept in a bed at the base, thinking that would suffice to get me back again later.
After returning to spawn, installing a warp plugin (and learning that /warp comes from Essentials), rebooting the server, and teleporting to some other coordinates to install their warps, I tried killing my avatar to return it to its bed. Instead of waking up in bed, it reappeared at spawn. Since my friends had long ago signed off for the night, I couldn’t just teleport to them. And I hadn’t written down the base’s coordinates. How could I get back?
Some digging in the docs revealed that there does not appear to be any console command to get a server to disclose the last seen location, or even the bed location, of an arbitrary player to an administrator. However, the server must know something about the players, because it will usually remember where their beds were when they rejoin the game.
On the server, there is a world/playerdata/ directory, containing one file per player that the server has ever seen. The file names are the player UUIDs, which can be pasted into this tool to turn them into usernames. But I skipped the tool, because the last modified timestamps on the files told me which two belonged to the friends who had both been at our base. So, I copied a .dat file that appeared to correspond to a player whose location or bed location would be useful to me. Running file on the file pointed out that it was gzipped, but unzipping it and checking the result for anything useful with strings yielded nothing comprehensible.
The wiki reminded me that the .dat was NBT-encoded. The recommended NBT Explorer tool appeared to require a bunch of Mono runtime stuff to be compatible with Linux, so instead I grabbed some code that claimed to be a Python NBT wrapper to see if it would do anything useful. With some help from its examples, I retrieved the player’s bed location:
from nbt import *
n = nbt.NBTFile("myfile.dat",'rb')
print("x=%s, y=%s, z=%s" % (n["SpawnX"], n["SpawnY"], n["SpawnZ"]))
Teleporting to those coordinates revealed that this was indeed the player’s bed, at the base I’d been looking all over for!
The morals of this story are twofold: First, I should not quit writing down coordinates I care about on paper, and second, Minecraft-adjacent programming is still not my idea of a good time.
Toy hypercube construction
I think hypercubes are neat, so I tried to make one out of string to play with. In the process, I discovered that there are surprisingly many ways to fail to trace every edge of a drawing of a hypercube exactly once with a single continuous line.
kubectl unable to recognize STDIN
Or, Stupid Error Of The Day. I’m talking to a GCP’s Kubernetes engine through several layers of intermediate tooling, and kubectl is failing:
subprocess.CalledProcessError: Command '['kubectl', 'apply', '--record', '-f', '-']' returned non-zero exit status 1.
Above that, in the wall of other debug info, is an error of the form:
error: unable to recognize "STDIN": Get https://11.22.33.44/api?timeout=32s: dial tcp 11.22.33.44:443: i/o timeout
This error turned out to have such a retrospectively obvious fix that nobody else seems to have published it.
When setting up the cluster on which kubectl was failing, I added the IP from which my tooling would access it, and hit the “done” button to save my changes. (That’s under the Authorized Networks section in “kubernetes engine -> clusters -> edit cluster” if you’re looking for it in the GCP console.) However, the “done” button is only one of the two required steps to save changes: One also must scroll all the way to the bottom of the page and press the “save” button there.
So if you’re here because you Googled that error, go recheck that you really do have access to the cluster on which you’re trying to kubectl apply. Good luck!
What to bring to CCC Camp next time
I took last week off work and attended CCC camp, which was wonderful on a variety of axes. I packed light, but through the week I noted some things it’d be worth packing less-lightly for.
So, here are my notes on what it’d be worth bringing if or when I attend it again:
Clothing
The site is dusty, extremely hot through the day, and quite cold at night. Fashion ranges from “generic nerd” to hippie, rave, and un-labelably eccentric. There is probably no wrong thing to wear, though I didn’t see a single suit or tie. A full base layer and a silk sleeping bag liner improve comfort at night. A big hat, or even an umbrella, offers protection from the day star.
I was glad to have 3 pairs of shoes: Lightweight waterproof sandals for showering, sturdier sandals for walking around in all day, and boots for early mornings and late nights. I saw quite a few long coats and even cloaks at night, and their inhabitants all looked very comfortably warm.
Doing sink laundry was more inconvenient at camp than for ordinary travel, and I was glad to have packed to minimize it.
A small comfortable bag, or large pockets in every outfit, are essential for keeping track of one’s wallet, phone, map, and water bottle.
I occasionally found myself wishing that I’d brought a washable dust mask, usually around midafternoon when camp became one big dust cloud.
Campsite Amenities
Covering a tent in space blankets makes it look like a baked potato, but keeps it warm and dark at night and cool through early afternoon. Space blankets are super cheap online, but difficult to find locally.
For a particularly opulent tent experience, consider putting a doormat outside the entrance as a place to remove shoes or clean dusty feet before going inside. I improvised a doormat with a trash bag, which was alright but the real thing would have been nicer to sit on.
Biertisch tables and benches are prevalent around camp, so you can usually find somewhere to sit, but it doesn’t hurt to bring a camp chair of the folding or inflatable variety. Inflatable stuff, from furniture to swimming pools, tended to survive fine on the ground.
I was glad to have brought a full sized towel rather than a tiny travel one. A shower caddy or bag to carry soap, washcloth, hair stuff, and clean clothes would have been handy, though I improvised one from another bag that I had available.
String and duct tape came in predictably handy in customizing my campsite.
Electronics
DECT phones are very fun at camp, but easy to pocket dial with. This is solved by finding the lock feature on the keypad, or picking a flip phone. I was shy about publishing my number and location in the phonebook, but after seeing how helpful the directory was for people to get ahold of new acquaintances for important reasons, I would be more public about my temporary number in the future.
Electricity is a limited resource but sunlight isn’t. Many tents sport portable solar panels. For those whose electronics have non-European plugs, a power strip from home is a good idea.
I packed a small headlamp and used it pretty much every day. Even with it, I found myself occasionally wishing that I’d brought a small LED lantern as well.
A battery to recharge cell phones is good to have as well, especially if you don’t run power to your tent. A battery can be left charging unattended in all kinds of public places where one would never leave one’s phone or laptop.
Food
Potable water is free, both still and sparkling. Perhaps I’ve been spoiled by the quality of the tap water at my home, but I wished that I’d brought water flavorings to mask the local combination of minerals.
I brought a small medical kit, from which I ended up using or sharing some aspirin, ibuprofin, antihistamines, and lots of oral rehydration salt packets.
Meals were available for free (with donations gratefully accepted) at several camps for everyone, and at the Heaven kitchen for volunteers. There were also a variety of food carts with varyingly priced dishes. The food carts outside the gates in front of the venue were good for an icecream or fresh veggie snack, which were harder to find within camp.
Savory meals and all kinds of drinks were everywhere, but there didn’t seem to be any place nearby to just pick up straight chocolate. Small, nonperishable snacks like that are worth getting at a grocery before arrival, since they’re not readily available on the grounds.
Other
If any of the special skills that your nerd friends ask you for help with require tools, bring them. I happen to always carry a needle and thread when traveling, and ended up using them to repair a giant inflatable computer-controlled sculpture.
A hammock, and something to shade it with, came in very handy and would be worth bringing again. There were lots of trees, and it might have been entertaining to set up a slackline for passers-by to fall off of, but I don’t think it’d be worth the weight of carrying one internationally.
Night time is basically a futuristic art show as well as a party. There’s no such thing as too much electroluminescent wire or too many LEDs, whether for decorating your camp or yourself. As a music party, it’s also extremely loud, so I was glad to have brought earplugs. Comfortable earplugs also improve sleep; music goes till 3 or 4 AM in many places and early risers start making noise around 8 or 9.
Camp has a lake, in which it’s popular to float large inflatable animals, especially unicorns. I saw more big inflatable unicorn floaties being used around camps as extra seating than being used in the lake, though.
There’s a railway that goes around camp, and sometimes runs a steam train. I won’t say you should rig a little electric cart to fit its rails and drive around on it, but somebody did and looked like they were having a really wonderful time.
Bikes, and lots of folding bikes, were everywhere. Scooters, skateboards, and all sorts of other wheeled contrivances, often electric, were also prevalent. The only rolling transportation that I didn’t see at all around camp were roller blades and skates, because the ground is probably too rough for them.
I ran out of stickers, and wished I’d brought more. I didn’t see as many pins as some conferences have.
A small notebook also came in handy. Each day, I checked both the stage schedule and the calendar to find the official and unofficial events which looked interesting, and noted their times on paper. It was consistently convenient to have a means of jotting down notes which didn’t risk running out of battery. Flipping through the book afterwards, about 1/4 of its contents is actually pictures I drew to explain various concepts to people I was chatting with, a few pages are daily schedule notes, and the rest is about half notes on things that presenters said and half ideas I jotted down to do something with later.
I was glad to have brought cash rather than just cards, not only for food but also because many workshops had a small fee to cover the cost of the materials that they provided.
Camp Advice
Nobody even tries to maintain a normal sleep schedule. People sleep when they’re tired, and do stuff when they aren’t. Talks and events tend to be scheduled from around noon to around midnight. I don’t think it would be possible to attend camp with a rigorous plan for what to every day and both stick to that plan and get the most out of the experience.
In shared spaces, people pick the lowest common denominator of language – at several workshops, even those initially scheduled to be held in German, presenters proactively asked if any attendees needed it to be in English then switched to English if asked. Behind-the-scenes, such as in the volunteers’ kitchen, I found that this was reversed: Everyone speaks German, and only switches to give you instructions if you specifically ask for English. Plenty of attendees have no German at all and get along fine.
Volunteer! If something isn’t happening how it should, fix it, or ask “how can I help?”. Volunteering an hour or two for filing badges or washing dishes is a great way to make new friends and see another side of how camp works.
More on Mentorship
Last year, I wrote about some of the aspirations which motivated my move from Mozilla Research to the CloudOps team. At the recent Mozilla All Hands in Whistler, I had the “how’s the new team going?” conversation with many old and new friends, and that repetition helped me reify some ideas about what I really meant by “I’d like better mentorship”.
Rustacean Hat Pattern
Based on feedback from the crab plushie pattern, I took more pictures this time.
There are 40 pictures of the process below the fold.
When searching an error fails
This blog has seen a dearth of posts lately, in part because my standard post formula is “a public thing had a poorly documented problem whose solution seems worth exposing to search engines”. In my present role, the tools I troubleshoot are more often private or so local that the best place to put such docs has been an internal wiki or their own READMEs.
This change of ecosystem has caused me to spend more time addressing a different kind of error: Those which one really can’t just Google.
Running a Python3 script in the right place every time
I just wrote a thing in a private repo that I suspect I’ll want to use again later, so I’ll drop it here.
The situation is that there’s a repo, and I’m writing a script which shall live in the repo and assist users with copying a project skeleton into its own directory.
The script, newproject, lives in the bin directory within the repo.
The script needs to do things from the root of the repository for the paths of its file copying and renaming operations to be correct.
If it was invoked from somewhere other than the root of the repo, it must thus change directory to the root of the repo before doing any other operations.
The snippet that I’ve tested to meet these constraints is:
# chdir to the root of the repo if needed
if __file__.endswith("/bin/newproject"):
os.chdir(__file__.strip("/bin/newproject"))
if __file__ == "newproject":
os.chdir("..")
In code review, it was pointed out that this simplifies to a one-liner:
os.chdir(os.path.join(os.path.dirname(__file__), '..'))
This will keep working right up until some malicious or misled individual moves the script to an entirely different location within the repository or filesystem and tries to run it from there.
CFP tricks 1
Or, “how to make a selection committee do one of the hard parts of your job as a speaker for you”. For values of “hard parts” that include fine-tuning your talk for your audience.
Skill Tree Balancing with a Job Move
I’ve recently identified some ways in which my former role wasn’t setting me up for career success, and taken steps to remedy them. Since not everybody lucks into this kind of process like I did, I’d like to write a bit about what I’ve learned in case it offers some reader a useful new framework for thinking about their skills and career growth.
Tl;dr: I’m moving from Research to Cloud Ops within Mozilla. The following wall of text and silly picture are a brain dump of new ideas about skills and career growth that I’ve built through the process.
Why an ops career
Disclaimers: Not all tasks that come to a person in an ops role meet my definition of ops tasks. Advanced ops teams move on from simple problems and choose more complex problems to solve, for a variety of reasons. This post contains generalizations, and all generalizations have counter-examples. This post also refers to feelings, and humans often experience different feelings in response to similar stimuli, so yours might not be like mine.
It’s been a great “family reunion” of FOSS colleagues and peers in the OSCON hallway track this week. I had a conversation recently in which I was asked “Why did you choose ops as a career path?”, and this caused me to notice that I’ve never blogged about this rationale before.
Thoughts on retiring from a team
The Rust Community Team has recently been having a conversation about what a team member’s “retirement” can or should look like. I used to be quite active on the team but now find myself without the time to contribute much, so I’m helping pioneer the “retirement” process. I’ve been talking with our subteam lead extensively about how to best do this, in a way that sets the right expectations and keeps the team membership experience great for everyone.
Nota bene: This post talks about feelings and opinions. They are mine and not meant to represent anybody else’s.
Slacking from Irssi
UPDATE: SLACK DECIDED THIS SHOULD NO LONGER BE POSSIBLE AND IT WILL NOT WORK ANY MORE
My IRC client helps me work efficiently and minimize distraction. Over the years, I’ve configured it to behave exactly how I want: Notifying me when topics I care about are under discussion, and equally as important, refraining from notifications that I don’t want. Since my IRC client is developed under the GPL, I have confidence that the effort I put into customizing it to improve my workflow will never be thrown out by a proprietary tool’s business decisions.
But the point of chat is to talk to other humans, and a lot of humans these days are choosing to collaborate on Slack. Slack has its pros and cons, but some of the drawbacks can be worked around using open technologies.
Some northwest area tech conferences and their approximate dates
Somebody asked me recently about what conferences a developer in the pacific northwest looking to attend more FOSS events should consider. Here’s an incomplete list of conferences I’ve attended or hear good things about, plus the approximate times of year to expect their CFPs.
The Southern California Linux Expo (SCaLE) is a large, established Linux and FOSS conference in Pasadena, California. Look for its CFP at socallinuxexpo.org in September, and expect the conference to be scheduled in late February or early March each year.
If you don’t mind a short flight inland, OpenWest is a similar conference held in Utah each year. Look for its CFP in March at openwest.org, and expect the conference to happen around July. I especially enjoy the way that OpenWest brings the conference scene to a bunch of fantastic technologists who don’t always make it onto the national or international conference circuit.
Moving northward, there are a couple DevOps Days conferences in the area: Look for a PDX DevOps Days CFP around March and conference around September, and keep an eye out in case Boise DevOps Days returns.
If you’re into a balance of intersectional community and technical content, consider OSBridge (opensourcebridge.org) held in Portland around June, and OSFeels (osfeels.com) held around July in Seattle.
In Washington state, LinuxFest Northwest (CFP around December, conference around April, linuxfestnorthwest.org) in Bellingham, and SeaGL (seagl.org, CFP around June, conference around October) in Seattle are solid grass-roots FOSS conferences. For infosec in the area, consider toorcamp (toorcamp.toorcon.net, registration around March, conference around June) in the San Juan Islands.
And finally, if a full conference seems like overkill, considering attending a BarCamp event in your area. Portland has CAT BarCamp (catbarcamp.org) at Portland State University around October, and Corvallis has Beaver BarCamp (beaverbarcamp.org) each April.
This is by no means a complete list of conferences in the area, and I haven’t even tried to list the myriad specialized events that spring up around any technology. Meetup, and calagator.org for the Portland area, are also great places to find out about meetups and events.
User is not authorized to perform iam:ChangePassword.
Summary: A user who is otherwise authorized to change their password may get this error when attempting to change their password to a string which violates the Password Policy in your IAM Account Settings.
So, I was setting up the 3rd or 4th user in a small team’s AWS account, and I did the usual: Go to the console, make a user, auto-generate a password for them, tick “force them to change their password on next login”, chat them the password and an admonishment to change it ASAP.
It’s a compromise between convenience and security that works for us at the moment, since there’s all of about 10 minutes during which the throwaway credential could get intercepted by an attacker, and I’d have the instant feedback of “that didn’t work” if anyone but the intended recipient performed the password change.
So, the 8th or 10th user I’m setting up, same way as all the others, gets that error on the change password screen: “User is not authorized to perform iam:ChangePassword”. Oh no, did I do their permissions wrong? I try explicitly attaching the Amazon’s IAMUserChangePassword policy to them, because that should fix their not being authorized, right? Wrong; they try again and they’re still “not authorized”.
OK, I have their temp password because I just gave it to them, so I’ll pop open private browsing and try logging in as them.
When I try putting in the same autogenerated password at the reset screen, I get “Password does not conform to the account password policy.”. This makes sense; there’s a “prevent password reuse” policy enabled under Account Settings within IAM.
OK, we won’t reuse the password. I’ll just set it to that most seekrit string, “hunter2”. Nope, the “User is not authorized to perform iam:ChangePassword” is back. That’s funny, but consistent with the rules just being checked in a slightly funny order.
Then, on a hunch, I try the autogenerated password with a 1 at the end as the new password. It changes just fine and allows me to log in! So, the user did have authorization to change their password all along... they were just getting an actively misleading error message about what was going wrong.
So, if you get this “User is not authorized to perform iam:ChangePassword” error but you should be authorized, take a closer look at the temporary password that was generated for you. Make sure that your new password matches or exceeds the old one for having lowercase letters, uppercase letters, numbers, special characters, and total length.
When poking at it some more, I discovered that one also gets the “User is not authorized to perform iam:ChangePassword” message when one puts an invalid value into the “current password” box on the change password screen. So, check for typos there as well.
This yak shave took about an hour to pin down the fact that it was the contents of the password string generating the permissions error, and I haven’t been able to find the error string in any of Amazon’s actual documentation, so hopefully I’ve said “User is not authorized to perform iam:ChangePassword” enough times in this post that it pops up in search results for anyone else frustrated by the same challenge.
Better remote teaming with distributed standups
Agile development’s artifact of the daily stand-up meeting is a great idea. In theory, the whole team should stand together (sitting or eating makes meetings take too long) for about 5 minutes every morning. Each person should comment on:
- What they did since yesterday
- What they plan on doing today
- Any blockers, thigns they’re waiting on to be able to get work done
- Anything else
And then, 5 minutes later, everybody gets back to work. But do they really?
Saying Ping
There’s an idiom on IRC, and to a lesser extent other more modern communication media, where people indicate interest in performing a real-time conversation with someone by saying “ping” to them. This effectively translates to “I would like to converse with you as soon as you are available”.
The traditional response to “ping” is to reply with “pong”. This means “I am presently available to converse with you”.
If the person who pinged is not available at the time that the ping’s recipient replies, what happens? Well, as soon as they see the pong, they re-ping (either by saying “ping” or sometimes “re-ping” if they are impersonating a sufficiently complex system to hold some state).
This attempt at communication, like “phone tag”, can continue indefinitey in its default state.
It is an inefficient use of both time and mental overhead, since each missed “ping” leaves the recipient with a vague curiosity or concern: “I wonder what the person who pinged wanted to talk to me about...”. Additionally, even if both parties manage to arrange synchronous communication at some point in the future, there’s the very real risk that the initiator may forget why they originally pinged at all.
There is an extremely simple solution to the inefficiency of waiting until both parties are online, which is to stick a little metadata about your question onto the ping. “Ping, could you look issue # xyz?” “Ping, can we chat about your opinions on power efficiency sometime?”. And yet there appears to be a decent correlation between people I regard as knowing more than I do about IRC etiquette, and people who issue pings without attaching any context to them.
If you do this, and happen to read this, could you please explain why to me sometime?
Resumes: 1 page or more?
Some of my IRC friends are job hunting at the moment, so I’ve been proofreading resumes. These friends are several years into their professional careers at this point, and I’ve found it really interesting to see what they include and exclude to make the best use of their resumes’ space.
Opinion: Levels of Safety Online
The Mozilla All-Hands this week gave me the opportunity to explore an exhibit about the “Mozilla Worldview” that Mitchell Baker has been working on. The exhibit sparked some interesting and sometimes heated discussion (as direct result of my decision to express unpopular-sounding opinions), and helped me refine my opinions on what it means for someone to be “safe” on the internet.
Spoiler: I think that there are many different levels of safety that someone can have online, and the most desirable ones are also the most difficult to attain.
Obligatory disclaimer: These are my opinions. You’re welcome to think I’m wrong. I’d be happy to accept pull requests to this post adding tools for attaining each level of safety, but if you’re convinced I’m wrong, the best place to say that would be your own blog. Feel free to drop me a link if you do write up something like that, as I’d enjoy reading it!
Salt: Successful ping but highstate says “minion did not return”
Today I was setting up some new OSX hosts on Macstadium for Servo’s build cluster. The hosts are managed with SaltStack.
After installing all the things, I ran a test ping and it looked fine:
user@saltmaster:~$ salt newbuilder test.ping
newbuilder:
True
However, running a highstate caused Salt to claim the minion was non-responsive:
user@saltmaster:~$ salt newbuilder state.highstate
newbuilder:
Minion did not return. [No response]
Googling this problem yielded a bunch of other “minion did not return” kind of issues, but nothing about what to do when the minion sometimes returns fine and other times does not.
The fix turned out to be simple: When a test ping succeeds but a longer-running state fails, it’s an issue with the master’s timeout setting. The timeout defaults to 5 seconds, so a sufficiently slow job will look to the master like the minion was unreachable.
As explained in the Salt docs, you can bump the timeout by adding the line timeout: 30 (or whatever number of seconds you choose) to the file /etc/salt/master on the salt master host.
Advice on storing encryption keys
I saw an excellent question get some excellent infosec advice on IRC recently. I’m quoting the discussion here because I expect that I’ll want to reference it when answering others’ questions in the future.
Tech Internship Hunting Ideas
A question from a computer science student crossed one of my IRC channels recently:
Them: what is the best way to fish for internships over the summer?
Glassdoor?
Me: It depends on what kind of internship you're looking for. What kind of
internship are you looking for?
Them: Computer Science, anything really.
This caused me to type out a lot of advice. I’ll restate and elaborate on it here, so that I can provide a more timely and direct summary if the question comes up again.
Philosophy of Job Hunting
My opinion on job hunting, especially for early-career technologists, is that it’s important to get multiple offers whenever possible. Only once one has a viable alternative can one be said to truly choose a role, rather than being forced into it by financial necessity.
In my personal experience, cultivating multiple offers was an important step in disentangling impostor syndrome from my career choices. Multiple data points about one’s skills being valued by others can help balance out an internal monologue about how much one has yet to learn.
If you disagree that cultivating simulataneous opportunities then politely declining all but the best is a viable internship hunting strategy, the rest of this post may not be relevant or interesting to you.
Identifying Your Options
To get an internship offer, you need to make a compelling application to a company which might hire you. I find that a useful first step is to come up with a list of such companies, so you can study their needs and determine what will make your application interest them.
Use your social network. Ask your peers about what internships they’ve had or applied for. Ask your mentors whether they or their friends and colleagues hire interns.
When you ask someone about their experience with a company, remember to ask for their opinion of it. To put that opinion into perspective, it’s useful to also ask about their personal preferences for what they enjoy or hate about a workplace. Knowing that someone who prefers to work with a lot of background noise enjoyed a company’s busy open-plan office can be extremely useful if you need silence to concentrate! Listening with interest to a person’s opinions also strengthens your social bond with them, which never hurts if it turns out they can help you get into a company that you feel might be a good fit.
Use LinkedIn, Hacker News, Glassdoor, and your city’s job boards. The broader a net you cast to start with, the better your chances of eventually finding somewhere that you enjoy. If your job hunt includes certain fields (web dev, DevOps, big data, whatever), investigate whether there’s a meetup for professionals in that field in your region. If you have the opportunity to give a short talk on a personal project at such a meetup, do it and make sure to mention that you’re looking for an internship.
Identify your own priorities
Now that you have a list of places which might concievably want to hire you, it’s time to do some introspection. For each field that you’ve found a prospective company in, try to answer the question “What makes you excited about working here?”.
You do not have to have know what you want to do with your life to know that, right now, you think DevOps or big data or frontend development is cool.
You do not have to personally commit to a single passion at the expense of all others – it’s perfectly fine to be interested in several different languages or frameworks, even if the tech media tries to pit them against each other.
However, for each application, it’s prudent to only emphasize your interests in that particular field. It’s a bit of a faux pas to show up to a helpdesk interview and focus the whole time on your passion for building robots, or vice versa. And acting equally interested in every other field will cause an employer to doubt that you’re necessarily the best fit for a specialized role... So in an interview, try not to stray too far from the value that you’re able to deliver to that company.
This is also a good time to identify any deal-breakers that would cause you to decline a prospective internship. Are you ok with relocating? Is there some tool or technology that would cause you to dread going to work every day?
I personally think that it’s worth applying even to a role that you know you wouldn’t accept an offer from when you’re early in your career. If they decide to interview you, you’ll get practice experiencing a real interview without the pressure of “I’ll lose my chance at my dream job if I mess this up!”. Plus if they extend an offer to you, it can help you calibrate the financial value of your skills and negotiate with employers that you’d actually enjoy.
Craft an excellent resume
I talk about this elsewhere.
There are a couple extra notes if you’re applying for an internship:
1) Emphasize the parts of your experience that relate most closely to what each employer values. If you can, it’s great to use the same words for skills that were used in the job description.
2) The bar for what skills go on your resume is lower when you have less experience. Did you play with Docker for a weekend recently and use it to deploy a toy app? Make sure to include that experience.
Practice, Practice, Practice
If you’re uncomfortable with interviewing, do it until it becomes second nature. If your current boss supports your internship search, do some mock interviews with them. If you’re nervous about things going wrong, have a friend roleplay as a really bad interview with you to help you practice coping strategies. If you’ll be in front of a panel of interviewers, try to get a panel of friends to gang up on you and ask tough questions!
To some readers this may be obvious, but to others it’s worth pointing out that you should also practice wearing the clothes that you’ll wear to an interview. If you wear a tie, learn to tie it well. If you wear shirts or pants that need to be ironed, learn to iron them comptently. If you wear shoes that need to be shined, learn to shine them. And if your interview will include lunch, learn to eat with good table manners and avoid spilling food on yourself.
Yes, the day-to-day dress codes of many tech offices are solidly in the “sneakers, jeans, and t-shirt” category for employees of all levels and genders. But many interviewers, especially mid- to late-career folks, grew up in an age when dressing casually at an interview was a sign of incompetence or disrespect. Although some may make an effort to overcome those biases, the subconscious conditioning is often still there, and you can take advantage of it by wearing at least business casual.
Apply Everywhere
If you know someone at a company where you’re applying, try to get their feedback on how you can tailor your resume to be the best fit for the job you’re looking at! They might even be able to introduce you personally to your potential future boss.
I think it’s worth submitting a good resume to every company which you identify as being possibly interested in your skills, even the ones you don’t currently think you want to work for. Interview practice is worth more in potential future salary than the hours of your time it’ll take at this point in your career.
Follow Up
If you don’t hear back from a company for a couple weeks, a polite note is order. Restate your enthusiasm for their company or field, express your understanding that there are a lot of candidates and everything is busy, and politely solicit any feedback that they may be able to offer about your application. A delayed reply does not always mean rejection.
If you’re rejected, follow up to thank HR for their time.
If you’re invited to interview, reply promptly and set a time and date. For a virtual or remote interview, only offer times when you’ll have access to a quiet room with a good network connection.
Interview Excellently
I don’t have any advice that you won’t find a hundred times over on the rest of the web. The key points are:
- Show up on time, looking respectable
- Let’s hope you didn’t lie on your resume
- Restate each question in your answer
- It’s ok not to know an answer – state what you would do if you encountered the problem at work. Would you Google a certain phrase? Ask a colleague? Read the manual?
- Always ask questions at the end. When in doubt, ask your interviewer what they enjoy about working for the company.
Keep Following Up
After your interview, write to whoever arranged it and thank the interviewers for their time. For bonus points, mention something that you talked about in the interview, or include the answer to a question that you didn’t know off the top of your head at the time.
Getting an Offer
Recruiters don’t usually like to disclose the details of offers in writing right away. They’ll often phone you to talk about it. You do not have to accept or decline during that first call – if you’re trying to stall for a bit more time for another company to get back to you, an excuse like “I’ll have to run that by my family to make sure those details will work” is often safe.
Remember, though, that no offer is really a job until both you and the employer have signed a contract.
Declining Offers
If you’ve applied to enough places with a sufficiently compelling resume, you’ll probably have multiple offers. If you’re lucky, they’ll all arrive around the same time.
If you wish to decline an offer from a company whom you’re certain you don’t want to work for, you can practice your negotiation skills. Read up on salary negotiation, try to talk the company into making you a better offer, and observe what works and what doesn’t. It’s not super polite to invest a bunch of their time in negotiations and then turn them down anyway, which is why I suggest only doing this to a place that you’re not very fond of.
To decline an offer without burning any bridges, be sure to thank them again for their time and regretfully inform them that you’ll be pursuing other opportunities at this time. It never hurts to also do them a favor like recommending a friend who’s job hunting and might be a good fit.
Again, though, don’t decline an offer until you have your actual job’s contract in writing.
Rust’s Community Automation
Here’s the text version, with clickable links, of my Automacon lightning talk today.
Setting a Freenode channel’s taxonomy info
Some recent flooding in a Freenode channel sent me on a quest to discover whether the network’s services were capable of setting a custom message rate limit for each channel. As far as I can tell, they are not.
However, the problem caused me to re-read the ChanServ help section:
/msg chanserv help
- ***** ChanServ Help *****
- ...
- Other commands: ACCESS, AKICK, CLEAR, COUNT, DEOP, DEVOICE,
- DROP, GETKEY, HELP, INFO, QUIET, STATUS,
- SYNC, TAXONOMY, TEMPLATE, TOPIC, TOPICAPPEND,
- TOPICPREPEND, TOPICSWAP, UNQUIET, VOICE,
- WHY
- ***** End of Help *****
Taxonomy is a cool word. Let’s see what taxonomy means in the context of IRC:
/msg chanserv help taxonomy
- ***** ChanServ Help *****
- Help for TAXONOMY:
-
- The taxonomy command lists metadata information associated
- with registered channels.
-
- Examples:
- /msg ChanServ TAXONOMY #atheme
- ***** End of Help *****
Follow its example:
/msg chanserv taxonomy #atheme
- Taxonomy for #atheme:
- url : http://atheme.github.io/
- ОХЯЕБУ : лололол
- End of #atheme taxonomy.
That’s neat; we can elicit a URL and some field with a cryllic and apparently custom name. But how do we put metadata into a Freenode channel’s taxonomy section? Google has no useful hits (hence this blog post), but further digging into ChanServ’s manual does help:
/msg chanserv help set
- ***** ChanServ Help *****
- Help for SET:
-
- SET allows you to set various control flags
- for channels that change the way certain
- operations are performed on them.
-
- The following subcommands are available:
- EMAIL Sets the channel e-mail address.
- ...
- PROPERTY Manipulates channel metadata.
- ...
- URL Sets the channel URL.
- ...
- For more specific help use /msg ChanServ HELP SET command.
- ***** End of Help *****
Set arbirary metadata with /msg chanserv set #channel property key value
The commands /msg chanserv set #channel email a@b.com and /msg chanserv set #channel property email a@b.com appear to function identically, with the former being a convenient wrapper around the latter.
So that’s how #atheme got their fancy cryllic taxonomy: Someone with the appropriate permissions issued the command /msg chanserv set #atheme property ОХЯЕБУ лололол.
Behaviors of channel properties
I’ve attempted to deduce the rules governing custom metadata items, because I couldn’t find them documented anywhere.
- Issuing a set property command with a property name but no value deletes the property, removing it from the taxonomy.
- A property is overwritten each time someone with the appropriate permissions issues a /set command with a matching property name (more on the matching in a moment). The property name and value are stored with the same capitalization as the command issued.
- The algorithm which decides whether to overwrite an existing property or create a new one is not case sensitive. So if you set ##test email test@example.com and then set ##test EMAIL foo, the final taxonomy will show no field called email and one field called EMAIL with the value foo.
- When displayed, taxonomy items are sorted first in alphabetical order (case insensitively), then by length. For instance, properties with the names a, AA, and aAa would appear in that order, because the initial alphebetization is case-insensitive.
- Attempting to place mIRC color codes in the property name results in the error “Parameters are too long. Aborting.” However, placing color codes in the value of a custom property works just fine.
Other uses
As a final note, you can also do basically the same thing with Freenode’s NickServ, to set custom information about your nickname instead of about a channel.
Adventures in Mercurial
I adore Git, but have needed to ramp up my Mercurial (Hg) skills recently to dig prior work related to my current tasks out of a repo’s history. Here are some things I’m learning:
Command Equivalences
As this tutorial so helpfully explains, the two VCSes aren’t all that dissimilar under their hoods. I condensed the command comparison table into a single page and printed it out for quick reference; a PDF is here.
Clone
The thing I want to clone lives at http://hg.mozilla.org/hgcustom/version-control-tools/file/tip/autoland.
Trying to clone the full URL yields a 404, but snipping the URL back to the top-level directory gets me the repo:
$ hg clone http://hg.mozilla.org/hgcustom/version-control-tools/
destination directory: version-control-tools
requesting all changes
adding changesets
adding manifests
adding file changes
added 4574 changesets with 10874 changes to 1971 files
updating to bookmark @
1428 files updated, 0 files merged, 0 files removed, 0 files unresolved
$ ls
version-control-tools
Examine Log
hg log | less shows me that each commit’s summary in this repo includes the part of the codebase it touches, and a bug number.
hg log | grep autoland: | less gives me the summaries of every commit that touched autoland, but I cannot show a commit from summary alone.
The Hg book helped me construct a filter that will show a unique revision ID onthe same line as each description.
hg log --template '{rev} {desc}\n' | grep autoland: is much more useful. It gives me the local ID of each changeset whose description included “autoland:”.
From here, I can use a bit more grep to narrow down the list of matching messages, then I’m ready to examine commits.
Examining Commits
That {rev} in my filter was the “repository-local changeset revision number”. For these examples I’ll examine revision 2589.
hg status --change 2589 lists the files that were touched by that revision, and hg export 2589 yields a full diff of the changes introduced.
This gets me enough information to make an appropriate set of changes, run the tests, and create my own commits!
Thinkpad 13 Trackpoint slowdown in i3 window manager
As has been mentioned on Reddit, the Thinkpad 13 trackpoint settings aren’t in the same place as those of older thinkpads. Despite some troubleshooting, I haven’t yet found what files to edit to adjust the trackpoint’s speed and sensitivity in Ubuntu 16.04.
The trackpoint has been slightly sluggish/unresponsive when I use the i3 window manager, and has additional intermittent slowdowns when using Chromium and Firefox in i3.
Although I don’t yet know the right way to fix trackpoint sensitivity on this machine, I accidentally discovered a highly effective workaround today:
- Log into Unity (the default desktop that Ubuntu ships with) and configure the mouse and input settings as desired
- Log out, and get back into i3wm
- Launch unity-settings-daemon
- And suddenly, the mouse works correctly the way it did in Unity!
I fully realize that this is a nasty hack around identifying and solving the actual problem, but it succeeds at making the mouse responsive while minimizing time spent troubleshooting.
Hieroglyph and Tinkerer Dependencies
In setting up virtualenvs for my slides and blog repos on my new laptop, I’ve been reminded that a variety of Sphinx-based tools require system dependencies as well as the ones in their virtualenvs.
Hieroglyph dependency issues
The error resulting from pip install -r requirements.txt ended with:
Command ".../virtualenv/bin/python2 -u -c
"import setuptools,
tokenize;__file__='/tmp/pip-build-lzbk_r/Pillow/setup.py';exec(compile(getattr(tokenize,
'open', open)(__file__).read().replace('\r\n', '\n'), __file__, 'exec'))"
install --record /tmp/pip-BNDc_6-record/install-record.txt
--single-version-externally-managed --compile --install-headers
/home/edunham/repos/slides/rustcommunity/v/include/site/python2.7/Pillow"
failed with error code 1 in /tmp/pip-build-lzbk_r/Pillow/
Its fix, from stackoverflow, was:
$ sudo apt-get install libtiff5-dev libjpeg8-dev zlib1g-dev libfreetype6-dev liblcms2-dev libwebp-dev tcl8.6-dev tk8.6-dev python-tk
$ pip install -r requirements.txt
Tinkerer depencencies, too!
pip install -r requirements.txt over in my blog repo yielded:
Command ".../virtualenv/bin/python2 -u -c "import setuptools,
tokenize;__file__='/tmp/pip-build-NVLSBY/lxml/setup.py';exec(compile(getattr(tokenize,
'open', open)(__file__).read().replace('\r\n', '\n'), __file__, 'exec'))"
install --record /tmp/pip-qD5QIe-record/install-record.txt
--single-version-externally-managed --compile --install-headers
/home/edunham/repos/site/v/include/site/python2.7/lxml" failed with error code
1 in /tmp/pip-build-NVLSBY/lxml/
The fix is again to install the missing system deps, on Ubuntu:
$ sudo apt-get install libxml2-dev libxslt-dev
$ pip install -r requirements.txt
That’s it! I’m writing this down for SEO on the specific errors at hand, since the first several useful hits are currently stackoverflow.
If you’re a pip developer reading this, please briefly contemplate whether it’d be worthwhile to have some built-in mechanism to translate common dependency errors to the appropriate system package names needed based on the OS on which the command is run.
CFPs Made Easier
Check out this post by Lucy Bain about how to come up with an idea for what to talk about at a conference. I blogged last year about how I turn abstracts into talks, as well. Now that the SeaGL CFP is open, it’s time to look in a bit more detail about the process of going from a talk idea to a compelling abstract.
In this post, I’ll walk you through some exercises to clarify your understanding of your talk idea and find its audience, then help you use that information to outline the 7 essential parts of a complete abstract.
Getting ready to write your abstract
Your abstract is a promise about what your talk will deliver. Have you ever gotten your hopes up for a talk based on its abstract, then attended only to hear something totally unrelated? You can save your audience from that disappointment by making sure that you present what your abstract says you will.
I find the abstract to be the hardest part of the talk to write, because it sets the stage for every other part of it. If your abstract is thorough and clear about what your talk will deliver, you can refer back to it throughout the writing process to make sure you’re including the information that your audience is there for!
For both you and your audience to get the most out of your talk, the following questions can help you refine your talk idea before you even start to write its abstract.
Why do you love this idea?
Start working on your abstract by taking some quick notes on why you’re excited about speaking on this topic. There are no wrong answers! Your reasons might include:
- Document a topic you care about in a format that works well for those who learn by listening and watching
- Impress a potential employer with your knowledge and skills
- Meet others in the community who’ve solved similar problems before, to advise you
- Recruit contributors to a project
- Force yourself to finish a project or learn more detail about a tool
- Save novices from a pitfall that you encountered
- Travel to a conference location that you’ve always wanted to visit
- Build your resume
- Or something else entirely!
Starting out by identifying what you personally hope to gain from giving the talk will help ensure that you make the right promises in your abstract, and get the right people into the room.
What’s your idea’s scope?
Make 2 quick little lists:
- Topics I really want this presentation to cover
- Topics I do not want this presentation to cover
Once you think that you have your abstract all sorted out, come back to these lists and make sure that you included enough topics from the first list, and excluded those from the second.
Who’s the conference’s target audience?
Keynotes and single-track conferences are special, but generally your talk does not have to appeal to every single person at the conference.
Write down all the major facts you know about the people who attend the conference to which you’re applying. How young or old might they be? How technically expert or inexperienced? What are their interests? Why are they there?
For example, here are some statements that I can make about the audience at SeaGL:
- Expertise varies from university students and random community members to long-time contributors who’ve run multiple FOSS projects.
- Age varies from a few school-aged kids (usually brought by speakers and attendees) to retirees.
- The audience will contain some long-term FOSS contributors who don’t program, and some relatively expert programmers who might have minimal involvement in their FOSS communities
- Most attendees will be from the vicinity of Seattle. It will be some attendees’ first tech conference. A handful of speakers are from other parts of the US and Canada; international attendees are a tiny minority.
- The audience comes from a mix of socioeconomic backgrounds, and many attendees have day jobs in fields other than tech.
- Attendees typically come to SeaGL because they’re interested in FOSS community and software.
Where’s your niche?
Now that you’ve taken some guesses about who will be reading your abstract, think about which subset of the conference’s attendees would get the most benefit out of the topic that you’re planning to talk about.
Write down which parts of the audience will get the most from your talk – novices to open source? Community leaders who’ve found themselves in charge of an IRC channel but aren’t sure how to administer it? Intermediate Bash users looking to learn some new tricks?
If your talk will appeal to multiple segments of the community (developers interested in moving into DevOps, and managers wondering what their operations people do all day?), write one question that your talk will answer for each segment.
You’ll use this list to customize your abstract and help get the right people into the room for your talk.
Still need an idea?
Conferences with a diverse audience often offer an introductory track to help enthusiastic newcomers get up to speed. If you have intermediate skills in a technology like Bash, Git, LaTeX, or IRC, offer an introductory talk to help newbies get started with it! Can you teach a topic that you learned recently in a way that’s useful to newbies?
If you’re an expert in a field that’s foreign to most attendees (psychology? beekeeping? Cray Supercomputer assembly language?), consider an intersection talk: “What you can learn from X about Y”. Can you combine your hobby, background, or day job with a theme from the conference to come up with something unique?
The Anatomy of an Abstract
There are many ways to structure a good abstract. Here are the 7 elements that I try to always include:
Set the scene with a strong introductory sentence, which reminds your target audience of your topic’s relevance to them. Some of mine have included:
- “Rust is a systems programming language that runs blazingly fast, prevents segfaults, and guarantees thread safety.”
- “Git is the most popular source code management and version control system in the open source community.”
- “When you’re new to programming, or self-taught with an emphasis on those topics that are directly relevant to your current project, it’s easy to skip learning about analyzing the complexity of algorithms.”
Ask some questions, which the talk promises to answer. These questions should be asked from the perspective of your target audience, which you identified earlier. This is the least essential piece of an abstract, and can be skipped if you make sure your exposition clearly shows that you understand your target audience in some other way. Here are a couple of questions I’ve used in abstracts that were accepted to conferences:
- “Do you know how to control what information people can discover about you on an IRC network?”
- “Is the project of your dreams ignoring your pull requests?”
Drop some hints about the format that the talk will take. This shows the selection commitee that you’ve planned ahead, and helps audience members select session that’re a good fit for their learning styles. Useful words here include:
- “Overview of”
- “Case study”
- “Demonstration”
- “Deep dive into”
- “Outline X principles for”
- “Live coding”
Identify what background knowledge the audience will need to get the talk’s benefit, if applicable. Being specific about this helps welcome audience members who’re undecided about whether the talk is applicable to them. Useful phrases include:
- “This talk will assume no background knowledge of...”
- “If you’ve used ____ to ____, ...”
- “If you’ve completed the ____ tutorial...”
State a specific benefit that audience members will get from having attended the talk. Benefits can include:
- “Halve your Django website’s page load times”
- “Get help on IRC”
- “Learn from ____‘s mistakes”
- “Ask the right questions about ____“
Reinforce and quantify your credibility. If you’re presenting a case study into how your company deployed a specific tool, be sure to mention your role on the team! For instance, you might say:
- “Presented by [the original author | a developer | a maintainer | a long-term user] of [the project], this talk will...”
End with a recap of the talk’s basic promise, and welcome audience members to attend.
These 7 pieces of information don’t have to each be in their own sentence – for instance, establishing your credibility and indicating the talk’s format often fit together nicely in a single sentence.
Once you’ve got all of the essential pieces of an abstract, munge them around until it sounds like concise, fluent English. Get some feedback on helpmeabstract.com if you’d like assistance!
Give it a title
Naming things is hard. Here are some assorted tips:
- Keep it under about 50 characters, or it might not fit on the program
- Be polite. Rude puns or metaphors might be eye-catching, but probably violate your conference or community’s code of conduct, and will definitely alienate part of your prospective audience.
- For general talks, it’s hard to go wrong with “Intro to ___” or “___ for ___ users”.
- The form “[topic]: A [history|overview|melodrama|case study|love story]” is generally reliable. Well, I’m kidding about “melodrama” and “love story”... Mostly.
- Clickbait is underhanded, but it works. “___ things I wish I’d known about ___”, anyone?
Good luck, and happy conferencing!
2ish weeks with the Thinkpad 13
I recently got a Thinkpad 13 to try replacing my X230 as a personal laptop. Here’s the relevant specs from my order confirmation:
| Battery | 3cell 42Wh |
| System Unit | 13&S2 IG i5-6200U NvPro |
| Camera | 720p HD Camera |
| AC Adapter and Power Cord | 45W 2pin US |
| Processor | Intel Core i5-6200U MB |
| Hard drive | 128GB SSD SATA3 |
| Keyboard Language | KYB SR ENG |
| Publication Language | PUB ENG |
| Total memory | 4GB DDR4 2133 SoDIMM |
| OS DPK | W10 Home |
| Pointing device | 3+2BCP NoFPR SR |
| Preload Language | W10 H64-ENG |
| Preload OS | Windows 10 Home 64 |
| Preload Type | Standard Image |
| TPM Setting | Software TPM Enabled |
| Display Panel | 13&S2 FHD IPS AG AL SR |
| WiFi wireless LAN adapters | Intel 8260AC+BT 2x2 vPro |
I picked mediocre CPU and RAM because the RAM’s easy to upgrade, and I’m curious about whether I actually need top-of-the-line CPUs to have an acceptable experience on a personal laptop.
Why the 13?
I had a few hard requirements for my next personal laptop:
- Trackpoint with buttons
- Decent key travel (the X1 carbon has 1.86mm and typing on it for too long made my hands hurt)
- USBC port
- Under $1,000
Plus a few nice-to-haves:
- Small and light are nice, including charger
- Screen not much worse than 1920x1080
- Good battery life
- Metal case and design for durability make me happy
- My house is already full of Thinkpad chargers, so a laptop that uses them helps reduce additional clutter
I’ll be the first to admit that this is an atypical set of priorities. My laptop is home to Git, Vim, and a variety of tools for interacting with the internet, so the superficial I/O differences matter more to me than the machine’s internal specs.
Things I like about the 13
- 2.1mm key travel is everything I hoped for. At least, I’ve used it all day and my hands don’t hurt.
- Battery life is pretty decent, and battery will be easy to replace when it starts to fail.
- Light-enough weight. Lighter charger than other Thinkpads I’ve had.
- Smallest Thinkpad charger that I’ve ever seen.
- Case screws are all captive.
- Mystery hole in the bottom case turns out to be a highly convenient hard shutdown button.
- Hinges feel pretty solid and hold the screen up nicely.
- No keyboard backlight. I dislike them.
- 4GB of RAM is a single stick, easy to add more (and I’ll need to for a smoother web browsing experience; neither Firefox nor Chromium is particularly happy with only 4GB)
- A vanilla Ubuntu 16.04 iso Just Worked for installing Linux. It must have shipped with whatever magic signatures were required to play nice with the new security measures, because the install process was delightfully non-thought-provoking.
- ~7mm plastic bezel between buttons and trackpad reduces likelihood of accidentally moving cursor when clicking.

- Screen’s the same as my X240, xrandr calls it 1920x1080 294mm x 165mm. This fits 211 columns of a default font, or 127 columns of a font that’s comfortably legible when the laptop is on the other side of my desk.
Nitpicks about the 13
- Color.
When I purchased mine at the end of April, only the silver chassis had a metal lid and shipped with a nice screen by default (the higher-res screen is available in the all-plastic black model for an additional charge). So now I own a non-black laptop for the first time since my Dell Latitude D410 in high school. The screen bezel and keys are black, though, and if I really cared I could probably paint the rest of it.
- Power button.

It feels horribly... squishy? There’s no satisfying click to tell me when I’ve pushed it far enough. Holding it for 10 seconds only sometimes shuts the laptop off (though there’s a reset switch on the mobo accessible by a paperclip-hole in the bottom panel which forces shutdown instantly when pushed). There’s a circle on the pwoer button that looks like it might be an LED, but it never lights up.
- Cutesy font.

This is a tiny nitpick, but they’ve changed the Lenovo logo on the lid, pre-BIOS boot screen, and screen bezel from the already-mediocre font to a super condescending, childish, roundy one. Fortunately the lid one is easily hidden under some stickers.
- Bottom panel held on by clips as well as screws.
More on this one in the disassembly section below, but I’m afraid they’ll break with how often I take my laptops apart.
- Mouse buttons feel cheap and plastic-ey.
They feel like thin plastic shells instead of solid buttons like on older Thinkpads. I’m not sure precisely why they feel that way, but it’s a reminder that you’re using a lower-end machine.
- Longest side is about 1cm greater than the short side of a TSA xray tub.
My X240 fits perfectly along the short end of the tub, leaving room for my shoes beside it. I have to use two tubs or separate my pair of shoes when putting the 13 through the scanner. (see, I wasn’t kidding when I said “nitpicks”)
- The Trackpoint top is not interchangeable with those of older Thinkpads.

The round part is the same size, but the square hole in the bottom is about 2mm to a side rather than the 4mm of the one on an x220 keyboard. Plus the cylinder bit is about 2mm long rather than the x220’s 3.5mm, so even with an adapter for the square hole, older trackpoints would risk leaving marks on the screen.
- The fan is a little loud.
I anticipate that this will get a lot less annoying when I upgrade to 16 or 32GB of ram and maybe tune it in software using thinkfan.
Thinkpad 13 partial disassembly photos
To get the bottom case off, pull all the visible screws and also remove the 3 tiny rubber feet from under the palm rest. I stuck my tiny rubber feet in a plastic bag and filed it away, because repeated removal would eventually destroy the glue and get them lost.

The bottom case comes off with a combination of sliding and prying. Getting it back on again requires sliding the palmrest edge just right, then snapping the sides and back on before the palm rest slips out of place. It’s tricky.

The battery is easily removed by pulling out a single (non-captive) screw. It seems to be a thin plastic wrapper around 3 cell phone batteries. The battery has no glue holding it in, just screws.

Here’s its guts, with battery removed.

Note the convenient hard power cycle button (accessible via a tiny hole in the bottom case when assembled), pair of RAM slots and SSD form factor, and airspace compartment that almost looks intended for hiding half a dozen very small items. The coin cell battery (in sky blue shrink wrap) flaps around awkwardly when the machine is disassembled, but at least it’s not glued down.
Reflections on my first live webcast
This morning, I participated in the O’Reilly Emerging Languages Webcast with my “Rust from a Scripting Background” talk. Here’s how it went.
Preparation
I was contacted about a month before my webcast and asked to present my OSCON talk as part of the event. I explained why my “How to learn Rust” talk didn’t sound like a good fit for the emerging languages webcast, and suggested the “Starting Rust from a Scripting Background” talk that I gave at my local Rust meetup recently as an alternative.
After we agreed on what talk would be suitable, O’Reilly’s Online Events Producers emailed me a contract to e-sign. The contract gives O’Reilly the opportunity to reuse and redistribute my talk from the webcast, and promises me a percentage of the proceeds if my recording is sold, licensed, or otherwise used to make them money.
During the week before the webcast, I did a test call in which an O’Reilly representative walked me through how to use the webcast software and verified that my audio was good on the phone I planned to use for the webcast.
A final copy of the slides for the webcast, in my option of PDF or Powerpoint, was due at 5pm the day before the event.
The Software (worked for me on Ubuntu)
O’Reilly Media provided an application called “Presentation Manager XD” from on24.com that presenters log into during the event.
According to my email from O’Reilly, the requirements for the event are:
- Slides - PowerPoint or PDF only please with no embedded video or audio. Screen ratio of 4:3
- Robust Internet connection
- Clear, reliable phone line.
- Windows 7 or 8 running IE 8+, Firefox 22+ or Chrome 27+
- Mac OS 10.6+ running Firefox 22+ or Chrome 27+
- Latest version of Flash Player
- If you plan to share your screen, you will need to install a small application - you will be prompted to install it the first time you log into the platform.
Some of these requirements are lies. I used Firefox 46.0 on Ubuntu 14.04. I did rewrite my slides in LibreOffice because it emits better PDFs than the HTML tools I normally use, but I was also looking for an excuse to rewrite them to clean up their organization.
I clicked around in the “Presentation Manager XD” UI and downloaded a file called “ON24-ScreenShare-plugin”, then chmod +x‘d it and executed it with ./ON24-ScreenShare-plugin. This caused Wine to run, install some Gecko stuff, and start the screenshare plugin sufficiently well to share my screen to the webcast tool.
I had to re-run the plugin in Wine after logging out of and back into my window manager, of course. Additionally, the screenshare window’s resizing is finicky. It’s fine to grab and drag the highlighted parts of the window’s border with the mouse, but the meta+click command with which one usually moves windows in i3 causes the sides of the screenshare window to move independently of each other.
Here’s what the webcast UI looked like during streaming, just at the end of the Kotlin talk while I was getting ready to start mine:
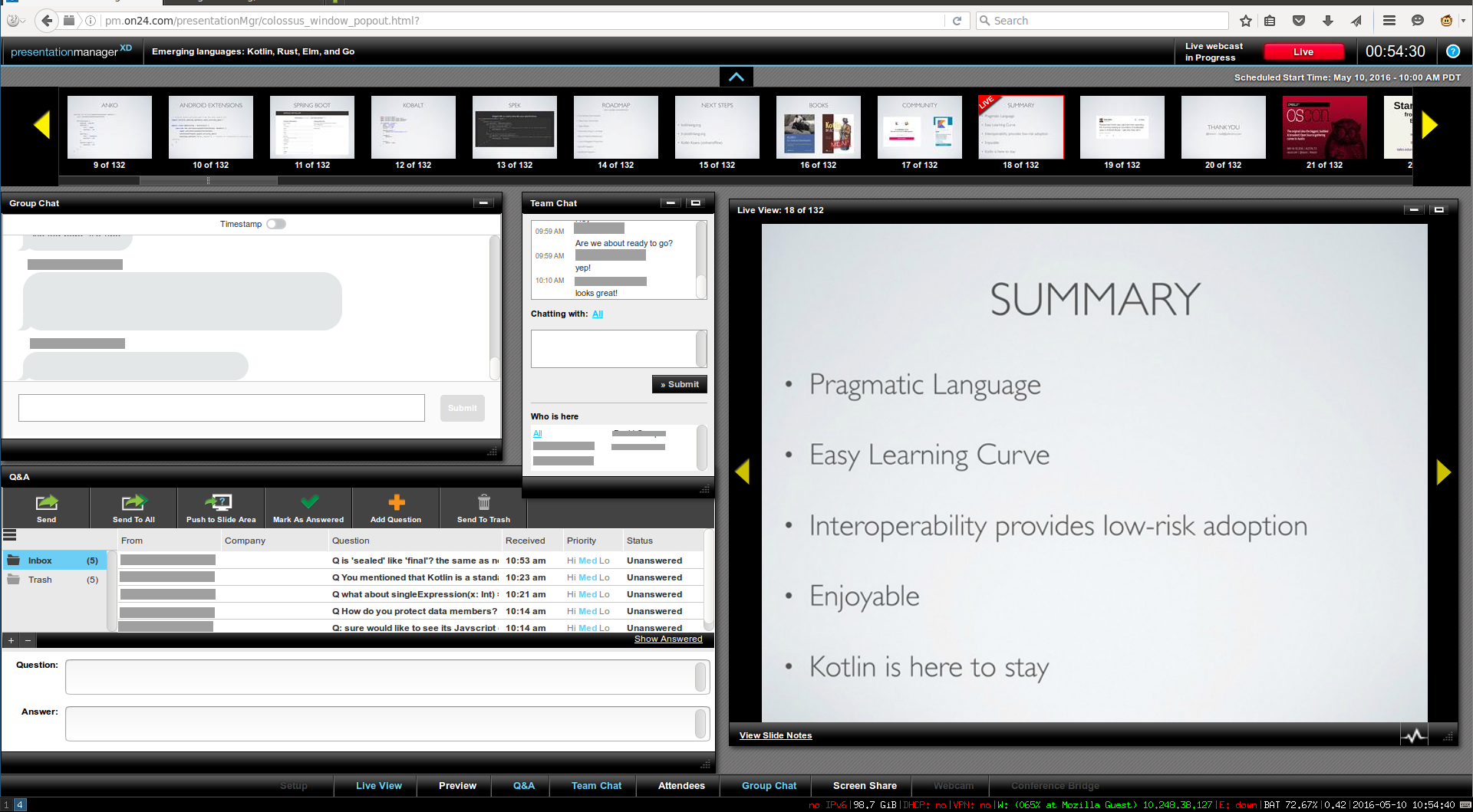
The Talk
As previously mentioned, I rewrote my talk in LibreOffice Impress – ostensibly to get a prettier PDF, but also because it’s been a month or two since I last prepared for it and re-writing helps me refresh my memory and verify that all my facts are up to date.
GUI-based slide editing is downright painful after using rst-based tools for so long, especially because LibreOffice has no good way to embed code samples out of the box. I ended up going with screenshots from the Rust playground, which were probably better than embedded code samples, but relearning how to edit slides like a regular person wasn’t a pleasant experience.
I took more notes than I normally do, since nobody on the webcast could see whether I was reciting or reading. I’m glad I did, as having the notes on a physical page in front of me was reassuring and helped me avoid missing any important points.
I rehearsed the timing of each section of my slides individually, since it naturally broke down into 7 or so discrete parts and I had previously calculated how much of my hour to allocate to each section. Most sections ran consistently over time when preparing, yet under time during the actual talk. The lesson here is to rehearse until I’m happy with a section and can make it the same duration twice in a row.
The experience of presenting a talk in a subjectively empty room made me realize just what high-bandwidth communication regular conferences are.
Pros:
- No need to worry about eye contact
- All the notes you want
- Can’t see anyone sleeping
- Chat channel allowed instant distribution of links
- Chat channel allowed expert attendees to help answer questions
- Presentation software allowed gracefully skipping slides, rather than the usual paging back and forth with the arrow keys
Cons:
- Can’t take quick surveys by show of hands
- Negligible feedback on how many people are there and their body language of engagement/disengagement
- Silences are super awkward
- Can’t see the shy attendees, in order to encourage participation
The audience asked fewer questions during the talk than I expected. Fortunately, they came up with plenty of questions at the end – extra fortunate because I overcompensated on time and finished my slides about 15 minutes before the end of my speaking slot!
Q&A was surprisingly relaxing, as it was totally up to me which questions to answer. I’ll admit that I did select in favor of those that I could answer concisely and eloquently, deferring the questions that didn’t make as much sense to think about them while I answered easier ones.
tl;dr
In my experience, presenting a webcast was lower-stress and comparably impactful to a conference talk.
For would-be presenters concerned about their or the audience’s appearance, the visual anonymity of a webcast could be a great place to start a speaking career.
Speakers accustomed to presenting in rooms full of humans should expect subtle feedback, like nods, smiles, and laughter, to be totally invisible in a webcast environment.
And if O’Reilly asks you to do a webcast with them, I’d say go for it – they made the whole experience as seamless and easy as possible.
Paths Into DevOps
Today, Carol asked me about how a current sysadmin can pivot into a junior “devops” role. 10 tweets into the reply, it became obvious that my thoughts on that type of transition won’t fit well into 140-character blocks.
My goal with this post is to catalog what I’ve done to reach my current level of success in the field, and outline the steps that a reader could take to mimic me.
Facets of DevOps
In my opinion, 3 distinct areas of focus have made me the kind of person from whom others solicit DevOps advice:
- Cultural background
- Technical skills
- Self-promotion
I place “cultural background” first because many people with all the skills to succeed at “DevOps” roles choose or get stuck with other job titles, and everyone touches a slightly different point on the metaphorical elephant of what “DevOps” even means.
Cultural Background
What does “DevOps” mean to you?
- Sysadmins who aren’t afraid of automation?
- 2 sets of job requirements for the price of 1 engineer?
- Developers who understand what the servers are actually doing?
- Reducing the traditional divide between “development” and “operations” silos?
- A buzzword that increases your number of weekly recruiter emails?
- People who use configuration management, aka “infrastructure as code”?
From my experiences starting Oregon State University’s DevOps Bootcamp training program, speaking on DevOps related topics at a variety of industry conferences, and generally being a professional in the field, I’ve seen the term defined all of those ways and more.
Someone switching from “sysadmin” to “devops” should clearly define how they want their day-to-day job duties to change, and how their skills will need to change as a result.
Technical Skills
The best way to figure out the technical skills required for your dream job will always be to talk to people in the field, and read a lot of job postings to see what you’ll need on your resume and LinkedIn to catch a recruiter’s eye.
In my opinion, the bare minimum of technical skills that an established sysadmin would need in order to apply for DevOps roles are:
- Use a configuration management tool – Chef, Puppet, Salt, or Ansible – to set up a web server in a VM.
- Write a script in Python to do something more than Hello World – an IRC bot or tool to gather data from an API is fine.
- Know enough about Git and GitHub to submit a pull request to fix something about an open source tool that other sysadmins use, even if it’s just a typo in the docs.
- Understand enough about continuous integration testing to use it on a personal project, such as TravisCI on a GitHub repo, and appreciate the value of unit and integration tests for software.
- Be able to tell a story about successfully troubleshooting a problem on a Linux or BSD server, and what you did to prevent it from happening again.
Keep in mind that your job in an interview is to represent what you know and how well you can learn new things. If you’re missing one of the above skills, go ask for help on how to build it.
Once you have all the experiences that I listed, you are no longer allowed to skip applying for an interesting role because you don’t feel you know enough. It’s the employer’s job to decide whether they want to grow you into the candiate of their dreams, and your job to give them a chance. Remember that a job posting describes the person leaving a role, and if you started with every skill listed, you’d probably be bored and not challenged to your full potential.
Self Promotion
“DevOps” is a label that engineers apply to themselves, then justify with various experiences and qualifications.
The path to becoming a community leader begins at engaging with the community. Look up DevOps-related conferences – find video recordings of talks from recent DevOps Days events, and see what names are on the schedules of upcoming DevOps conferences.
Look at which technologies the recent conferences have discussed, then look up talks about them from other events. Get into the IRC or Slack channels of the tools you want to become more expert at, listen until you know the answers to common questions, then start helping beginners newer than yourself.
Reach out to speakers whose talks you’ve enjoyed, and don’t be afraid to ask them for advice. Remember that they’re often extremely busy, so a short message with a compliment on their talk and a specific request for a suggestion is more likely to get a reply than overly vague requests. This type of networking will make your name familiar when their companies ask them to help recruit DevOps engineers, and can build valuable professional friendships that provide job leads and other assistance.
Contribute to the DevOps-related projects that you identify as having healthy communities. For configuration management, I’ve found that SaltStack is a particularly welcoming group. Find the source code on GitHub, examine the issue tracker, pick something easy, and submit a pull request fixing the bug. As you graduate to working on more challenging or larger issues, remember to advertise your involvment with the project on your LinkedIn profile!
Additionally, help others out by blogging what you learn during these adventures. If you ever find that Google doesn’t have useful results for an error message that you searched, write a blog post with the message and how you fixed it. If you’re tempted to bikeshed over which blogging platform to use, default to GitHub Pages, as a static site hosted there is easy to move to your own hosting later if you so desire.
Examine job postings for roles like you want, and make sure the key buzzwords appear on your LinkedIn profile wherever appropriate. A complete LinkedIn profile for even a relatively new DevOps engineer draws a surprising number of recruiters for DevOps-related roles. If you’re just starting out in the field, I’d recommend expressing interest in every opportunity that you’re contacted about, progressing to at least a phone interview if possible, and getting all the feedback you can about your performance afterwards. It’s especially important to interview at companies that you can’t see yourself enjoying a job at, because you can practice asking probing questions that tell you whether an employer will be a good fit for you. (check out this post for ideas).
Another trick for getting to an interview is to start something with DevOps in the name. It could be anything from a curated blog to a meetup to an online “book club” for DevOps-related papers, but leading something with a cool name seems to be highly attractive to recruiters. Another way to increase your visibility in the field is to give a talk at any local conference, especially LinuxFest and DevOpsDays events. Putting together an introductory talk on a useful technology only requires intermediate proficiency, and is a great way to build your personal brand.
To summarize, there are really 4 tricks to getting DevOps interviews, and you should interview as much as you can to get a feeling for what DevOps means to different parts of the industry:
- Contribute back to the open source tools that you use
- Network with established professionals
- Optimize your LinkedIn and other professional profiles to draw recruiters
- Be the founder of something.
Questions?
I collect interesting job search and interview advice links at the bottom of my resume repo readme.
I bolded each paragraph’s key points in the hopes of making them easier to read.
You’re welcome to reach out to me at blog @ edunham.net or @qedunham on Twitter if you have other questions. If I made a dumb typo or omitted some information in this post, either tell me about it or just throw a pull request at the repo to fix it and give yourself credit.
Persona and third-party cookies in Firefox
Although its front page claims we’ve deprecated persona, it’s the only way to log into the statusboard and Air Mozilla. For a long time, I was unable to log into any site using Persona from Firefox 43 and 44 because of an error about my browser not being configured to accept third-party cookies.
The support article on the topic says that checking the “always accept cookies” box should fix the problem. I tried setting “accept third-party cookies” to “Always”, and yet the error persisted. (setting the top-level history configuration to “always remember history” didn’t affect the error either).
Fortunately, there’s also an “Exceptions” button by the “Accept cookies from sites” checkbox. Editing the exceptions list to universally allow “http://persona.org” lets me use Persona in Firefox normally.

That’s the fix, but I don’t know whose bug it is. Did Firefox mis-balance privacy against convenience? Is the “always accept third-party cookies” setting’s failure to accept a cookie without an exception some strange edge case of a broken regex? Is Persona in the wrong for using a design that requires third-party cookies at all? Who knows!
Plushie Rustacean Pattern
I made a Rustacean. He’s cute. You can make one too.

You’ll Need
- A couple square feet of orange polar fleece, or any other orange fabric that won’t stretch or fray too much
- A handful of stuffing. I cannibalized a throw pillow.
- A needle and some orange thread
- Black and white fabric scraps and thread, or black and white embroidery floss, for making the face.
- Intermediate sewing skills
- This pattern
The Pattern
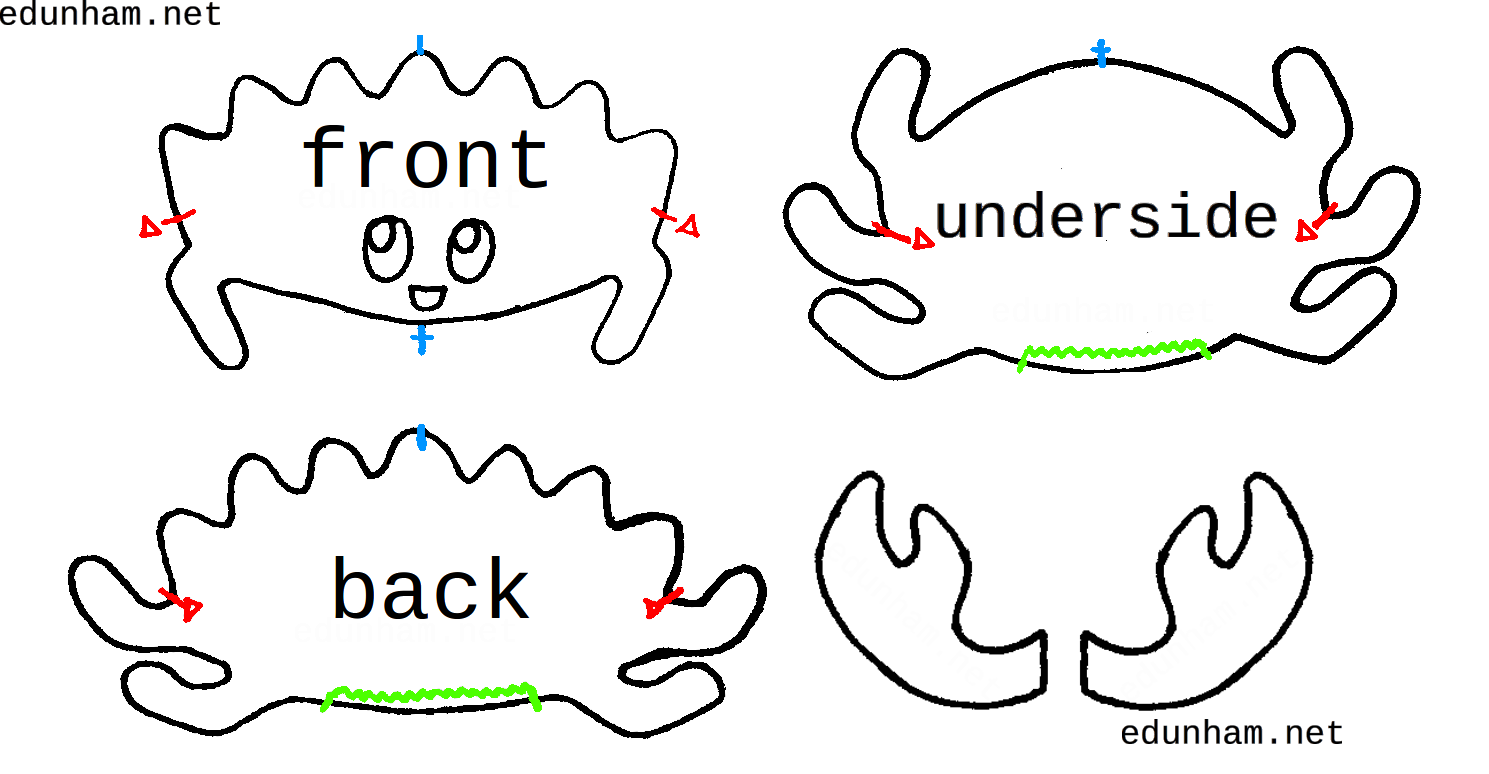
Get yourself a front, back, underside, and claw drawn on paper, either by printing them out or tracing from a screen. The front, back, and underside should have horizontal symmetry, except for the face placement. Make sure the points marked in red and blue on this pattern are noted on your paper.
Mine measure about 6” wide between the points marked in red.
Sewing vocabulary
- The right side of a fabric is what ends up on the outside of the finished item. The wrong side ends up where you can’t see it. Some fabrics have both sides the same; in that case, the wrong side is whichever one you feel like tracing the pattern onto.
- seam allowance is some extra fabric that ends up on the inside of the item when you’re done. The pattern above does not include seam allowance. This means that if you cut the fabric along the lines in the pattern, your finished rustacean will be tiny and sad and shaped wrong. You cut the paper along the lines, then trace it onto the fabric, then sew along the lines.
- applique is where you sew one piece of fabric onto the surface of another to make a design.
- There are a bunch of great youtube videos on basic sewing skills. Watch whichever ones you need.
Assembly
- Trace a front, a back, an underside, and the 2 claws onto the wrong side of your fabric with whatever will write on it without bleeding through. Make sure to transfer the blue centerline marks and the red three-point join marks.
- Cut out the shapes you just traced, leaving about 1” of margin around them. We’ll trim the seams properly later, so don’t worry about getting it exact.
- Find a couple claw-sized chunks of leftover fabric and pin one to the back of each claw (right sides together, of course).
- Sew around both claws, leaving the arm ends open so you can turn them. I find it’s easiest to backstitch, and you can get away with stitches up to about 1.5mm apart with normal weight polar fleece.
- Trim around the outside of the seams on the claws to leave about 1/4” seam allowance, and clip right up to the stitches in the concave spot. If you backstitched, make sure flip them over before trimming the seams so you don’t accidentally cut through the longer stitches.
- Turn the claws so the right side of the fabric is out and the seams are on the inside, and stuff them with stuffing or fabric scraps. A pair of wooden chopsticks from a fast food place are a great tool for turning and stuffing.
- Put the front and back pieces right sides together so the points marked in red and blue on the pattern line up. Pin them together.
- Sew from one red mark to the other along Ferris’s spiky back.
- Trim around the spikes leaving about 1/4” seam allowance, clipping right up to the seam in the concave spots.
- Figure out which side is front (hint, it has only 2 legs rather than 4). Imagine where Ferris’s little face will go when he’s finished. Now, pin both claws onto the right side of the front piece, so they’ll be oriented correctly when he’s done. If in doubt, pin the bottom front in place and turn the whole thing inside out to make sure the claws are right.
- Match the center front of the underside with the center of Ferris’s front (both have a blue + on the pattern). Be sure the pieces have their right sides together and the claws are sandwiched between them.
- Match the points marked with red triangles on each side of the front and underside together and pin them. If the claws are sticking out at this point, go back to step 10 and try again
- Sew from one red mark to the other to join Ferris’s front to the front of his underside. Put a few extra stitches in the part of the seam where his “arms”/claws are attached, to make sure they can’t be pulled out.
- Trim around the 2 tiny legs that you’ve sewn so far, with about 1/8” seam allowance.
- Now you can applique his face onto the right side of his front. Or embroider it if you know how. Cut the black and white felt scraps into face-shaped pieces and sew them down, giving Ferris whatever expression you want.
- Line up the 4 back legs on the underside and back pieces, and pin them right sides toether. Sew everything except the part marked in green – that’s the hole through which you’ll turn him inside out.
- Trim around those last 4 legs, leaving at least 1/8” seam allowance. Don’t cut away any more fabric from the bit marked in green. If you leave a bit of extra fabric around the leg seams, they’ll be harder to turn but require less stuffing.
- Turn Ferris right side out. Again, chopsticks or the non-pointy end of a barbeque skewer are useful for getting the pointy bits to do the right thing.
- Stuff Ferris with the filling. I filled mine quite loosely, because it makes him softer and more huggable. If you overfill his body, his spikes will look silly. If you overfill his legs, they’ll stick out in funny directions and not bend right.
- Tuck the seam allowance back into the hole through which you stuffed Ferris and sew it shut. Congratulations, you have your own toy crab!
The Finished Product

He’s cute, cuddly, and palm-sized. Lego dude for scale.
Could Rust have a left-pad incident?
The short answer: No.
What happened with left-pad?
The Node community had a lot of drama this week when a developer unpublished a package on which a lot of the world depended.
This was fundamentally possible because NPM offers an unpublish feature. Although the docs for unpublish admonish users that “It is generally considered bad behavior to remove versions of a library that others are depending on!” in large bold print, the feature is available.
What’s the Rust equivalent?
The Rust package manager, Cargo, is similar to NPM in that it helps users get the libraries on which their projects depend. Rust’s analog to the NPM index is crates.io.
The best explanation of Cargo’s robustness against unpublish exploits is the docs themselves:
cargo yank
Occasions may arise where you publish a version of a crate that actually ends up being broken for one reason or another (syntax error, forgot to include a file, etc.). For situations such as this, Cargo supports a “yank” of a version of a crate.:
$ cargo yank --vers 1.0.1 $ cargo yank --vers 1.0.1 --undoA yank does not delete any code. This feature is not intended for deleting accidentally uploaded secrets, for example. If that happens, you must reset those secrets immediately.
The semantics of a yanked version are that no new dependencies can be created against that version, but all existing dependencies continue to work. One of the major goals of crates.io is to act as a permanent archive of crates that does not change over time, and allowing deletion of a version would go against this goal. Essentially a yank means that all projects with a Cargo.lock will not break, while any future Cargo.lock files generated will not list the yanked version.
As Cargo author Alex Crichton clarified in a GitHub comment yesterday, the only way that it’s possible to remove code from crates.io is to compel the Rust tools team to edit the database and S3 bucket.
Even if a crate maintainer leaves the community in anger or legal action is taken against a crate, this workflow ensures that code deletion is only possible by a small group of people with the motivation and authority to do it in the way that’s least problematic for users of the Rust language.
For more information on the crates.io package and copyright policies, see this internals thread.
But I just want to left pad a string in Rust??
Although a left-pad crate was created as a joke, you should probably just use the format! built-in from the standard library.
Reducing SaltStack log verbosity for TravisCI
Servo has some Salt configs, hosted on GitHub, for which changes are smoke-tested on TravisCI before they’re deployed. Travis only shows the first 10k lines of log output, so I want to minimize the amount of extraneous information that the states print.
My salt state looks like::
android-sdk:
archive.extracted:
- name: {{ common.homedir }}/android/sdk/{{ android.sdk.version }}
- source: https://dl.google.com/android/android-sdk_{{
android.sdk.version }}-linux.tgz
- source_hash: sha512={{ android.sdk.sha512 }}
- archive_format: tar
- archive_user: user
- if_missing: {{ common.homedir }}/android/sdk/{{ android.sdk.version
}}/android-sdk-linux
- require:
- user: user
The output in TravisCI is::
ID: android-sdk
Function: archive.extracted
Name: /home/user/android/sdk/r24.4.1
Result: True
Comment: https://dl.google.com/android/android-sdk_r24.4.1-linux.tgz extracted in /home/user/android/sdk/r24.4.1/
Started: 17:46:25.900436
Duration: 19540.846 ms
Changes:
----------
directories_created:
- /home/user/android/sdk/r24.4.1/
- /home/user/android/sdk/r24.4.1/android-sdk-linux
extracted_files:
... 2755 lines listing one file per line that I don't want to see in the log
https://docs.saltstack.com/en/latest/ref/states/all/salt.states.archive.html has useful guidance on how to increase the tar state’s verbosity, but not to decrease it. This is because the extra 2755 lines aren’t coming from tar itself, but from Salt assuming that we want to know.
terse outputter settings
The outputter takes several state_output setting options. The terse option summarizes the result of each state into a single line.
There are a couple places you can set this:
- Invoke Salt with salt --state-output=terse hostname state.highstate
- Add the line state_output: terse to /etc/salt/minion, if you’re using salt-call
- Setting state_output_terse is apparently an option, though I can’t find any example of a real-world salt config that uses it
Setting the terse option in /etc/salt/minion dropped the output of a highstate from over 10,000 lines to about 2500.
Fixing sudo errors from the command line on OSX
The first symptom that I had made a terrible mistake showed up in an Ansible playbook:
GATHERING FACTS
***************************************************************
fatal: [...] => ssh connection closed waiting for a privilege escalation password prompt
fatal: [...] => ssh connection closed waiting for a privilege escalation password prompt
fatal: [...] => ssh connection closed waiting for sudo password prompt
fatal: [...] => ssh connection closed waiting for sudo password prompt
That looks like the sudo binary might be broken. To rule out Ansible problems, remote into the machine and try to use sudo:
administrators-Mac-mini:~ administrator$ sudo ls
sudo: effective uid is not 0, is sudo installed setuid root?
This meant that there was a file permissions problem:
working-host administrator$ ls -al /usr/bin/sudo
-r-s--x--x 1 root wheel 164560 Sep 9 2014 /usr/bin/sudo
broken-host administrator$ ls -al /usr/bin/sudo
-rwxrwxr-x 1 root wheel 164560 Sep 9 2014 /usr/bin/sudo
Now the problem is reduced to fixing the permissions. One does not simply sudo to root, because there’s no working sudo. However, Apple provides a utility which allows you to enable root login using only the administrator account’s permissions:
broken-host administrator$ dsenableroot
username = administrator
user password:
root password:
verify root password:
dsenableroot:: ***Successfully enabled root user.
The first password is the current one for the administrator account, and the other two should be the same string and will become the root account’s password.
After enabling root login, disconnect then SSH into the host as root:
broken-host root# chmod 4411 /usr/bin/sudo
And test that the fix fixed it:
broken-host root# su administrator
broken-host administrator$ sudo ls
Finally, clean up after yourself to inconvenience any future attackers:
broken-host administrator$ dsenableroot -d
Moral of the story: Errant chowns of /usr/bin are just as bad when they come from automation as when they come from humans.
Ansible, Vagrant, and changed host keys
Related to this bug, the Vagrant Ansible provisioner seems to ignore some system settings.
The symptom is that when you update a previously used Vagrant box, or otherwise change its host key, Ansible provisioning fails with the error:
fatal: [hostname] => SSH Error: Host key verification failed.
while connecting to 127.0.0.1:2200
It is sometimes useful to re-run the command using -vvvv, which prints SSH
debug output to help diagnose the issue.
The standard solution would be to forget about the old host key with ssh-keygen -R 127.0.0.1:2200 or ignore the change with export ANSIBLE_HOST_KEY_CHECKING=false.
If you trust the box not to be evil and expect its host key to change frequently due to your testing, a fix which the Ansible provisioner does respect is to add ansible.host_key_checking = false to the Vagrantfile, like:
Vagrant.configure(2) do |config|
...
config.vm.define "hostname" do |prodmaster|
hostname.vm.provision "ansible" do |ansible|
ansible.playbook = "provision/hostname.yaml"
ansible.sudo = true
ansible.host_key_checking = false
ansible.verbose = 'vvvv'
ansible.extra_vars = { ansible_ssh_user: 'vagrant'}
end
end
...
end
Vidyo with Ubuntu and i3wm
Mozilla uses Vidyo for virtual meetings across distributed teams. If it doesn’t work on your laptop, you can use the mobile client or book a meeting room in an office, but neither of those solutions is optimal when working from home.
Vidyo users within Mozilla can download a .deb or .rpm installer from v.mozilla.org. On Ubuntu, it’s easy to install the downloaded package with sudo dpkg -i path/to/the/file.deb.
The issue is that when you invoke VidyoDesktop from your launcher of choice (dmenu for me), i3 does what’s usually the right thing and makes the client fullscreen in a tile. This doesn’t allow the interface to pop up a floating window with the confirm dialog when you try to join a room, so you can’t.
mod + shift + space
Mod was alt by default last time I installed i3, but I’ve since remapped it to the window key (as IRC clients use alt for switching windows). Some people use caps lock as their mod key.
mod + shift + space makes the window floating, which allows it to pop up the confirmation dialog when you try to join a call.
Float windows by default
Alternately, stick the line:
for_window [class="VidyoDesktop"] floating enable
in your ~/.i3/config.
Installing Vidyo despite the libqt4-gui error
Edited as of May 2017: Recent Vidyos depend on a package that’s not available in Ubuntu’s repos. The easiest workaround is:
sudo dpkg -i --ignore-depends=libqt4-gui path/to/VidyoInstaller.deb
Are we ‘are we’ yet?
The Rust community, being founded and enjoyed by a variety of Mozilians, seems to have inherited the tradition of tracking top-level progress metrics using are we sites.
- Are we concurrent yet? tracks the progres of Rust’s concurrency ecosystem
- Are we web yet? tracks the status of Rust’s HTTP stack, web frameworks, and related libraries
- Are we IDE yet? provides a list of what features are supported for Rust per IDE, and links to the relevant tracking issues and RFCs
If this blog post was an ‘are we’ page itself, the big text at the top would probably say “Getting There”.
Buildbot WithProperties
Today, I copied an existing command from a Buildbot configuration and then modified it to print a date into a file.:
...
if "cargo" in component:
cargo_date_cmd = "echo `date +'%Y-%m-%d'` > " + final_dist_dir + "/cargo-build-date.txt"
f.addStep(MasterShellCommand(name="Write date to cargo-build-date.txt",
command=["sh", "-c", WithProperties(cargo_date_cmd)] ))
...
It broke:
Failure: twisted.internet.defer.FirstError: FirstError[#8, [Failure instance: Traceback (failure with no frames): <class 'twisted.internet.defer.FirstError'>: FirstError[#2, [Failure instance: Traceback: <type 'exceptions.ValueError'>: unsupported format character 'Y' (0x59) at index 14
Why? WithProperties.
It turns out that WithProperties should only be used when you need to interpolate strings into an argument, using either %s, %d, or %(propertyname)s syntax in the string.
The lesson here is Buildbot will happily accept WithProperties("echo 'this command uses no interpolation'") in a command argument, and then blow up at you if you ever change the command to have a % in it.
However, it appears that build steps run as MasterShellCommand``s without ``WithProperties do not display their name in the waterfall, but rather say “running” or “ran”.
Using Notty
I recently got the “Hey, you’re a Rust Person!” question of how to install notty and interact with it.
A TTY was originally a teletypewriter. Linux users will have most likely encountered the concept of TTYs in the context of the TTY1 interface where you end up if your distro fails to start its window manager. Since you use ctrl + alt + f[1,2,...] to switch between these interfaces, it’s easy to assume that “TTY” refers to an interactive workspace.
Notty itself is only a virtual terminal. Think of it as a library meant as a building block for creating graphical terminal emulators. This means that a user who saw it on Hacker News and wants to play around should not ask “how do I install notty”, but rather “how do I run a terminal emulator built on notty?”.
Easy Mode
Get some Rust:
curl -sf https://raw.githubusercontent.com/brson/multirust/master/blastoff.sh | sh
multirust update nightly
Get the system dependencies:
sudo apt-get install libcairo2-dev libgdk-pixbuf2.0 libatk1.0 libsdl-pango-dev libgtk-3-dev
Run Notty:
git clone https://github.com/withoutboats/notty.git
cd notty/scaffolding
multirust run nightly cargo run
And there you have it! As mentioned in the notty README, “This terminal is buggy and feature poor and not intended for general use”. Notty is meant as a library for building graphical terminals, and scaffolding is only a minimal proof of concept.
How much knowledge do you need to give a conference talk?
I was recently asked an excellent question when I promoted the LFNW CFP on IRC:
As someone who has never done a talk, but wants to, what kind of knowledge do you need about a subject to give a talk on it?
If you answer “yes” to any of the following questions, you know enough to propose a talk:
- Do you have a hobby that most tech people aren’t experts on? Talk about applying a lesson or skill from that hobby to tech! For instance, I turned a habit of reading about psychology into my Human Hacking talk.
- Have you ever spent a bunch of hours forcing two tools to work with each other, because the documentation wasn’t very helpful and Googling didn’t get you very far, and built something useful? “How to build ___ with ___” makes a catchy talk title, if the thing you built solves a common problem.
- Have you ever had a mentor sit down with you and explain a tool or technique, and the new understanding improved the quality of your work or code? Passing along useful lessons from your mentors is a valuable talk, because it allows others to benefit from the knowledge without taking as much of your mentor’s time.
- Have you seen a dozen newbies ask the same question over the course of a few months? When your answer to a common question starts to feel like a broken record, it’s time to compose it into a talk then link the newbies to your slides or recording!
- Have you taken a really interesting class lately? Can you distill part of it into a 1-hour lesson that would appeal to nerds who don’t have the time or resources to take the class themselves? (thanks lucyw for adding this to the list!)
- Have you built a cool thing that over a dozen other people use? A tutorial talk can not only expand your community, but its recording can augment your documentation and make the project more accessible for those who prefer to learn directly from humans!
- Did you benefit from a really great introductory talk when you were learning a tool? Consider doing your own tutorial! Any conference with beginners in their target audience needs at least one Git lesson, an IRC talk, and some discussions of how to use basic Unix utilities. These introductory talks are actually better when given by someone who learned the technology relatively recently, because newer users remember what it’s like not to know how to use it. Just remember to have a more expert user look over your slides before you present, in case you made an incorrect assumption about the tool’s more advanced functionality.
I personally try to propose talks I want to hear, because the dealine of a CFP or conference is great motivation to prioritize a cool project over ordinary chores.
Buildbot and EOFError
More SEO-bait, after tracking down an poorly documented problem:
# buildbot start master
Following twistd.log until startup finished..
2016-01-17 04:35:49+0000 [-] Log opened.
2016-01-17 04:35:49+0000 [-] twistd 14.0.2 (/usr/bin/python 2.7.6) starting up.
2016-01-17 04:35:49+0000 [-] reactor class: twisted.internet.epollreactor.EPollReactor.
2016-01-17 04:35:49+0000 [-] Starting BuildMaster -- buildbot.version: 0.8.12
2016-01-17 04:35:49+0000 [-] Loading configuration from '/home/user/buildbot/master/master.cfg'
2016-01-17 04:35:53+0000 [-] error while parsing config file:
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/twisted/internet/defer.py", line 577, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "/usr/local/lib/python2.7/dist-packages/twisted/internet/defer.py", line 1155, in gotResult
_inlineCallbacks(r, g, deferred)
File "/usr/local/lib/python2.7/dist-packages/twisted/internet/defer.py", line 1099, in _inlineCallbacks
result = g.send(result)
File "/usr/local/lib/python2.7/dist-packages/buildbot/master.py", line 189, in startService
self.configFileName)
--- <exception caught here> ---
File "/usr/local/lib/python2.7/dist-packages/buildbot/config.py", line 156, in loadConfig
exec f in localDict
File "/home/user/buildbot/master/master.cfg", line 415, in <module>
extra_post_params={'secret': HOMU_BUILDBOT_SECRET},
File "/usr/local/lib/python2.7/dist-packages/buildbot/status/status_push.py", line 404, in __init__
secondaryQueue=DiskQueue(path, maxItems=maxDiskItems))
File "/usr/local/lib/python2.7/dist-packages/buildbot/status/persistent_queue.py", line 286, in __init__
self.secondaryQueue.popChunk(self.primaryQueue.maxItems()))
File "/usr/local/lib/python2.7/dist-packages/buildbot/status/persistent_queue.py", line 208, in popChunk
ret.append(self.unpickleFn(ReadFile(path)))
exceptions.EOFError:
2016-01-17 04:35:53+0000 [-] Configuration Errors:
2016-01-17 04:35:53+0000 [-] error while parsing config file: (traceback in logfile)
2016-01-17 04:35:53+0000 [-] Halting master.
2016-01-17 04:35:53+0000 [-] Main loop terminated.
2016-01-17 04:35:53+0000 [-] Server Shut Down.
This happened after the buildmaster’s disk filled up and a bunch of stuff was manually deleted. There were no changes to master.cfg since it worked perfectly.
The fix was to examine master.cfg to see where the HttpStatusPush was created, of the form:
c['status'].append(HttpStatusPush(
serverUrl='http://build.servo.org:54856/buildbot',
extra_post_params={'secret': HOMU_BUILDBOT_SECRET},
))
Digging in the Buildbot source reveals that persistent_queue.py wants to unpickle a cache file from /events_build.servo.org/-1 if there was nothing in /events_build.servo.org/. To fix this the right way, create that file and make sure Buildbot has +rwx on it.
Alternately, you can give up on writing your status push cache to disk entirely by adding the line maxDiskItems=0 to the creation of the HttpStatusPush, giving you:
c['status'].append(HttpStatusPush(
serverUrl='http://build.servo.org:54856/buildbot',
maxDiskItems=0,
extra_post_params={'secret': HOMU_BUILDBOT_SECRET},
))
The real moral of the story is “remember to use logrotate.
Who would you hire?
If you’re using open source as a portfolio to make yourself a more competitive job candidate, it can feel like you have to start your own project to show off your skills.
In the words of one job seeker I chatted with recently, “I feel like most of my contributions [to other peoples’ projects] aren’t that significant or noteworthy”. Here’s a thought experiment to justify including projects to which you contribute, even without a leadership role, on your resume:
Imagine you want to hire a coder.
Candidate A always works alone and refuses to contribute to a project if it doesn’t make her look like a rockstar.
Candidate B triages the unglamorous issues that affect multiple users, and steadily produces small, self-contained fixes that avoid introducing new bugs.
When the situation is framed in these terms, I hope that it’s obvious which coder you’d want on your team.
When writing your resume, there’s only space to include a few of the many activities in which you invest your time. It’s tempting to only include your biggest, highest-profile solo projects, while disregarding those projects to which you’ve made a small but steady stream of useful contributions.
Reread your resume from the perspective of someone who hasn’t met you yet and has only the information in that document available to form a first impression of your character. Which of the 2 hypothetical coders does it make you sound like? Is that how you really are?
Troubleshooting stunnel
Today I’ve learned a few things aout how stunnel works. The main takeaway is that Googling for specific errors in the stunnel log is incredibly unhelpful, resulting in a variety of mailing list posts with no replies. Tracking an error message through the source of the program doesn’t lead to any useful comments, either. So here’s some SEO bait with concrete troubleshooting suggestions.
Questions about Open Source and Design
Today, I posed a question to some professional UI and UX designers:
How can an open source project without dedicated design experts collaborate with amateur, volunteer designers to produce a well-designed product?
They revealed that they’ve faced similar collaboration challenges, but knew of neither a specific process to solve the problem nor an organization that had overcome it in the past.
Have you solved this problem? Have you tried some process or technique and learned that it’s not able to solve the problem? Email me (design@edunham.net) if you know of an open source project that’s succeeded at opening their design as well, and I’ll update back here with what I learn!
In no particular order, here are some of the problems that we were talking about:
- Non-designers struggle to give constructive feedback on design. I can say “that’s ugly” or “that’s hard to use” more easily than I can say “here’s how you can make it better”.
- Projects without designers in the main decision-making team can have a hard time evaluating the quality of a proposed design.
- Non-designers struggle to articulate the objective design needs of their projects, so design remains a single monolithic problem rather than being decomposed into bite-sized, introductory issues the way code problems are.
- Volunteer designers have a difficult time finding open source projects to get involved with.
- Non-designers don’t know the difference between different types of design, and tend to bikeshed on superficial, obvious traits like colors when they should be focusing on more subtle parts of the user experience. We as non-designers are like clients who ask for a web site without knowing that there’s a difference between frontend development, back end development, database administration, and systems administration.
- The tests which designers apply to their work are often almost impossible to automate. For instance, I gather that a lot of user interaction testing involves watching new users attempt to complete a task using a given design, and observing the challenges they encounter.
Again, if you know of an open source project that’s overcome any of these challenges, please email me at design@edunham.net and tell me about it!
Linode vs AWS
I’m examining a Linode account in order to figure out how to switch the application its instances are running to AWS. The first challenge is that instance types in the main dashboard are described by arbitrary numbers (“UI Name” in the chart below), rather than a statistic about their resources or pricing. Here’s how those magic numbers line up to hourly rates and their corresponding monthly price caps:
| RAM | Hourly $ | Monthly $ | UI Name | Cores | GB SSD |
|---|---|---|---|---|---|
| 1GB | $0.015/hr | $10/mo | 1024 | 1 | 24 |
| 2GB | $0.03/hr | $20/mo | 2048 | 2 | 48 |
| 4GB | $0.06/hr | $40/mo | 4096 | 4 | 96 |
| 8GB | $0.12/hr | $80/mo | 8192 | 6 | 192 |
| 16GB | $0.24/hr | $160/mo | 16384 | 8 | 384 |
| 32GB | $0.48/hr | $320/mo | 32768 | 12 | 768 |
| 48GB | $0.72/hr | $480/mo | 49152 | 16 | 1152 |
| 64GB | $0.96/hr | $640/mo | 65536 | 20 | 1536 |
| 96GB | $1.44/hr | $960/mo | 98304 | 20 | 1920 |
AWS “Equivalents”
AWS T2 instances have burstable performance. M* instances are general-purpose; C* are compute-optimized; R* are memory-optimized. *3 instances run on slightly older Ivy Bridge or Sandy Bridge processors, while *4 instances run on the newer Haswells. I’m disergarding the G2 (GPU-optimized), D2 (dense-storage), and I2 (IO-optmized) instance types from this analysis.
Note that the AWS specs page has memory in GiB rather than GB. I’ve converted everything into GB in the following table, since the Linode specs are in GB and the AWS RAM amounts don’t seem to follow any particular pattern that would lose information in the conversion.
Hourly price is the Linux/UNIX rate for US West (Northern California) on 2015-12-03. Monthly price estimate is the hourly price multiplied by 730.
| Instance | vCPU | GB RAM | $/hr | $/month |
|---|---|---|---|---|
| t2.micro | 1 | 1.07 | .017 | 12.41 |
| t2.small | 1 | 2.14 | .034 | 24.82 |
| t2.medium | 2 | 4.29 | .068 | 49.64 |
| t2.large | 2 | 8.58 | .136 | 99.28 |
| m4.large | 2 | 8.58 | .147 | 107.31 |
| m4.xlarge | 4 | 17.18 | .294 | 214.62 |
| m4.2xlarge | 8 | 34.36 | .588 | 429.24 |
| m4.4xlarge | 16 | 68.72 | 1.176 | 858.48 |
| m4.10xlarge | 40 | 171.8 | 2.94 | 2146.2 |
| m3.medium | 1 | 4.02 | .077 | 56.21 |
| m3.large | 2 | 8.05 | .154 | 112.42 |
| m3.xlarge | 4 | 16.11 | .308 | 224.84 |
| m3.2xlarge | 8 | 32.21 | .616 | 449.68 |
| c4.large | 2 | 4.02 | .138 | 100.74 |
| c4.xlarge | 4 | 8.05 | .276 | 201.48 |
| c4.2xlarge | 8 | 16.11 | .552 | 402.96 |
| c4.4xlarge | 16 | 32.21 | 1.104 | 805.92 |
| c4.8xlarge | 36 | 64.42 | 2.208 | 1611.84 |
| c3.large | 2 | 4.02 | .12 | 87.6 |
| c3.xlarge | 4 | 8.05 | .239 | 174.47 |
| c3.2xlarge | 8 | 16.11 | .478 | 348.94 |
| c3.4xlarge | 16 | 32.21 | .956 | 697.88 |
| c3.8xlarge | 32 | 64.42 | 1.912 | 1395.76 |
| r3.large | 2 | 16.37 | .195 | 142.35 |
| r3.xlarge | 4 | 32.75 | .39 | 284.7 |
| r3.2xlarge | 8 | 65.50 | .78 | 569.4 |
| r3.4xlarge | 16 | 131 | 1.56 | 1138.8 |
| r3.8xlarge | 32 | 262 | 3.12 | 2277.6 |
Comparison
Linode and AWS do not compare cleanly at all. The smallest AWS instance to match a given Linode type’s RAM typically has fewer vCPUs and costs more in the region where I compared them. Conversely, the smallest AWS instance to match a Linode type’s number of cores often has almost double the RAM of the Linode, and costs substantially more.
Switching from Linode to AWS
When I examine the Servo build machines’ utilization graphs via the Linode dashboard, it becomes clear that even their load spikes aren’t fully utilizing the available CPUs. To view memory usage stats on Linode, it’s necessary to configure hosts to run the longview client. After installation, the client begins reporting data to Linode immediately.
After a few days, these metrics can be used to find the smallest AWS instance whose specs exceed what your application is actually using on Linode.
Sources:
Giving Thanks to Rust Contributors
It’s the day before Thanksgiving here in the US, and the time of year when we’re culturally conditioned to be a bit more public than usual in giving thanks for things.
As always, I’m grateful that I’m working in tech right now, because almost any job in the tech industry is enough to fulfill all of one’s tangible needs like food and shelter and new toys. However, plenty of my peers have all those material needs met and yet still feel unsatisfied with the impact of their work. I’m grateful to be involved with the Rust project because I know that my work makes a difference to a project that I care about.
Rust is satisfying to be involved with because it makes a difference, but that would not be true without its community. To say thank you, I’ve put together a little visualization for insight into one facet of how that community works its magic:
The stats page is interactive and available at http://edunham.github.io/rust-org-stats/. The pretty graphs take a moment to render, since they’re built in your browser.
There’s a whole lot of data on that page, and you can scroll down for a list of all authors. It’s especially great to see the high impact that the month’s new contributors have had, as shown in the group comparison at the bottom of the “natural log of commits” chart!
It’s made with the little toy I wrote a while ago called orglog, which builds on gitstat to help visualize how many people contribute code to a GitHub organization. It’s deployed to GitHub Pages with TravisCI (eww) and nightli.es so that the Rust’s organization-wide contributor stats will be automatically rebuilt and updated every day.
If you’d like to help improve the page, you can contribute to gitstat or orglog!
PSA: Docker on Ubuntu
$ sudo apt-get install docker
$ which docker
$ docker
The program 'docker' is currently not installed. You can install it by typing:
apt-get install docker
$ apt-get install docker
Reading package lists... Done
Building dependency tree
Reading state information... Done
docker is already the newest version.
0 upgraded, 0 newly installed, 0 to remove and 13 not upgraded.
Oh, you wanted to run a docker container? The docker package in Ubuntu is some window manager dock thingy. The docker binary that runs containers comes from the docker.io system package.
$ sudo apt-get install docker.io
$ which docker
/usr/bin/docker
Also, if it can’t connect to its socket:
FATA[0000] Post http:///var/run/docker.sock/v1.18/containers/create: dial
unix /var/run/docker.sock: permission denied. Are you trying to connect to a
TLS-enabled daemon without TLS?
you need to make sure you’re in the right group:
sudo usermod -aG docker <username>; newgrp docker
(thanks, stackoverflow!)
Installing Rust without root
I just got a good question from a friend on IRC: “Should I ask my university’s administration to install Rust on our shared servers?” The answer is “you don’t have to”.
Pick one of the two following sets of directions. I’d recommend using Multirust, because it automatically checks the packages it downloads and lets you switch between Rust versions trivially.
Multiple languages on TravisCI
Today I noticed an assumption which was making my life unnecessarily difficult: I assumed that if my .travis.yml said language: ruby on the first line, I was supposed to only run Ruby code from it.
Travis lets you run code much more arbitrary than that.
I did a bunch of tests on a toy repo to see what would happen if I ignored my preconceptions about how you can and can’t test stuff, and learned some interesting things:
- You can install PyPI packages in a test suite that’s technically Ruby, or gems in a test suite that’s technically Python.
- If your project is language:ruby, you need to sudo pip install dependencies. If it’s language:python, you can just gem install dependencies without sudo.
- If I specify multiple instances of language: or multiple build matrices, Travis uses the language whose build matrix occurs last. If I specify a Python matrix and then a Ruby one, the Ruby matrix will be run.
This is especially useful when testing or deployment requires hitting an API whose libraries are most up to date in a language other than that of the project.
Beyond Openhatch
Update: I’m now maintaining the issue aggregator list at http://edunham.net/pages/issue_aggregators.html
OpenHatch is a wonderful place to help new contributors find their first open source issues to work on. Their training materials are unparalleled, and the “projects submit easy bugs with mentors” model makes their list of introductory issues reliably high-quality.
However, once you know the basics of how to engage with an open source project, you’re no longer in the target audience for OpenHatch’s list. Where should you look for introductory issues when you want to get involved with a new project, but you’re already familiar with open source in general?
An excellent slide deck by Josh Matthews contains several answers to this question:
- issuehub.io scrapes GitHub by labels and language
- up-for-grabs has an opt-in list of projects looking for new contributors, and scrapes their issue trackers for their “jump in”, “up for grabs” or other “new contributors welcome” tags.
- If you’re looking for Mozilla-specific contributions outside of just code, What can I do for Mozilla? can help direct you into any of Mozilla’s myriad opportunities for involvement.
Additionally, the servo-starters page has a custom view of easy issues sorted by Servo’s project-specific tags.
GitHub Tricks
If you’re looking for open issues across all repos owned by a particular user or organization, you can use the search at https://github.com/pulls and specify the “user” (or org) in the search bar. For instance, this search will find all the unassigned, easy-tagged issues in the rust-lang org. Breaking down the search:
- user:rust-lang searches all repos owned by github.com/rust-lang. It could also be someone’s github username.
- is:open searches only open issues.
- no:assignee will filter out the issues which are obviously claimed. Note that some issues without an assignee set may still have a comment saying “I’ll do this!”, if it was claimed by a user who did not have permissions to set assignees and then not triaged.
- label:E-Easy uses my prior knowledge that most repos within rust-lang annotate introductory bugs with the E-easy tag. When in doubt, check the contributing.md file at the top level in the org’s most popular repository for an explanation of what various issue labels mean. If that information isn’t in the contributing file or the README, file a bug!
Am I missing your favorite introductory issue aggregator? Shoot me an email to ___@edunham.net (fill in the blank with anything; the email will get to me) with a link, and I’ll add it here if it looks good!
PSA: Pin Versions
Today, the website’s build broke. We made no changes to the tests, yet a wild dependency error emerged:
Generating...
Dependency Error: Yikes! It looks like you don't have redcarpet or one of
its dependencies installed. In order to use Jekyll as currently configured,
you'll need to install this gem. The full error message from Ruby is: 'cannot
load such file -- redcarpet' If you run into trouble, you can find helpful
resources at http://jekyllrb.com/help/!
Conversion error: Jekyll::Converters::Markdown encountered an error while
converting 'conduct.md':
redcarpet
ERROR: YOUR SITE COULD NOT BE BUILT:
------------------------------------
redcarpet
The command "jekyll build" exited with 1.
Although Googling the error was unhelpful, a bit more digging revealed that our last working build had been on Jekyll 2.5.3 and the builds breaking on a Redcarpet error all used 3.0.0.
The moral of the story is that where the .travis.yml said - gem install jekyll, it should have said - gem install jekyll -v 2.5.3.
SeaGL 2015 Retrospective
As well as nominally helping organize the event, I attended and spoke at SeaGL 2015 this weekend. The slides from my talk are here.
My talk drew an audience of perhaps a dozen people on Friday afternoon. I didn’t record this instance of the talk, but will probably give it at least one more time and be sure to record then.
One of the more useful tools I learned about is called myrepos. It lets you update all of the Git repositories on a machine at the same time, as well as other neat tricks like replaying actions that failed due to network problems. Its author has written a variety of other useful Git wrappers, as well.
Additionally, VCSH seems to be the “I knew somebody else wrote that already!” tool for keeping parts of a home directory in Git.
Upgrading Buildbot 0.8.6 to 0.8.12
Here are some quick notes on upgrading Buildbot.
System Dependencies
There are more now. In order to successfully install all of Buildbot’s dependencies with Pip, I needed a few more apt packages:
python-dev
python-openssl
libffi-dev
libssl-dev
Then for sanity’s sake make a virtualenv, and install the following packages. Note that having too new a sqlalchemy will break things.:
buildbot==0.8.12
boto
pyopenssl
cryptography
SQLAlchemy<=0.7.10
Virtualenvs
Troubleshooting compatibility issues with system packages on a host that runs several Python services with various dependency versions is predictably terrible.
The potential problem with switching to running Buildbot only from a virtualenv is that developers with access to the buildmaster might want to restart it and miss the extra step of activating the virtualenv. I addressed this by adding the command to activate the virtualenv (using the virtualenv’s absolute path) to the ~/.bashrc of the user that we run Buildbot as. This way, we’ve gained the benefits of having our dependencies consolidated without adding the cost of an extra workflow step to remember.
Template changes
Most of Buildbot’s status pages worked fine after the upgrade, but the console view threw a template error because it couldn’t find any variable named “categories”. The fix was to simply copy the new template from venv/local/lib/python2.7/site-packages/buildbot/status/web/templates/console.html to my-buildbot/master/templates/console.html.
That’s it!
Rust currently has these updates on the development buildmaster, but not yet (as of 10/14/2015) in prod.
Carrying credentials between environments
This scenario is simplified for purposes of demonstration.
I have 3 machines: A, B, and C. A is my laptop, B is a bastion, and C is a server that I only access through the bastion.
I use an SSH keypair helpfully named AB to get from me@A to me@B. On B, I su to user. I then use an SSH keypair named BC to get from user@B to user@C.
I do not wish to store the BC private key on host B.
SSH Agent Forwarding
I have keys AB and BC on host A, where I start. Host A is running ssh-agent, which is installed by default on most Linux distributions.
me@A$ ssh-add ~/.ssh/AB # Add keypair AB to ssh-agent's keychain
me@A$ ssh-add ~/.ssh/BC # Add keypair BC to the keychain
me@A$ ssh -A me@B # Forward my ssh-agent
Now I’m logged into host B and have access to the AB and BC keypairs. An attacker who gains access to B after I log out will have no way to steal the BC keypair, unlike what would happen if that keypair was stored on B.
See here for pretty pictures explaining in more detail how agent forwarding works.
Anyways, I could now ssh me@C with no problem. But if I sudo su user, my agent is no longer forwarded, so I can’t then use the key that I added back on A!
Switch user while preserving environment variables
me@B$ sudo -E su user
user@B$ sudo -E ssh user@C
What?
The -E flag to sudo preserves the environment variables of the user you’re logged in as. ssh-agent uses a socket whose name is of the form /tmp/ssh-AbCdE/agent.12345 to call back to host A when it’s time to do the handshake involving key BC, and the socket’s name is stored in me‘s SSH_AUTH_SOCK environment variable. So by telling sudo to preserve environment variables when switching user, we allow user to pass ssh handshake stuff back to A, where the BC key is available.
Why is sudo -E required to ssh to C? Because /tmp/sshAbCdE/agent.12345 is owned by me:me, and only the file’s owner may read, write, or execute it. Additionally, the socket itself (agent.12345) is owned by me:me, and is not writable by others.
If you must run ssh on B without sudo, chown -R /tmp/ssh-AbCdE to the user who needs to end up using the socket. Making them world read/writable would allow any user on the system to use any key currently added to the ssh-agent on A, which is a terrible idea.
For what it’s worth, the actual value of /tmp/ssh-AbCdE/agent.12345 is available at any time in this workflow as the result of printenv | grep SSH_AUTH_SOCK | cut -f2 -d =.
The Catch
Did you see what just happened there? An arbitrary user with sudo on B just gained access to all the keys added to ssh-agent on A. Simon pointed out that the right way address this issue is to use ProxyCommand instead of agent forwarding.
No, I really don’t want my keys accessible on B
See man ssh_config for more of the details on ProxyCommand. In ~/.ssh/config on A, I can put:
Host B
User me
Hostname 111.222.333.444
Host C
User user
Hostname 222.333.444.555
Port 2222
ProxyCommand ssh -q -w %h:%p B
So then, on A, I can ssh C and be forwarded through B transparently.
Ansible: Conditional role dependencies
I’ve recently been working on an Ansible role that applies to both Ubuntu and OSX hosts. It has some dependencies which are only needed on OSX. There doesn’t seem to be a central document on all the options available for solving this problem, so here are my notes.
Apache Licenses
At the bottom of the Apache 2.0 License file, there’s an appendix:
APPENDIX: How to apply the Apache License to your work.
...
Copyright [yyyy] [name of copyright owner]
...
Does that look like an invitation to fill in the blanks to you? It sure does to me, and has for others in the Rust community as well.
Today I was doing some licensing housekeeping and made the same embarrassing mistake.
This is a PSA to double check whether inviting blanks are part of the appendix before filling them out in Apache license texts.
X240 trackpoint speed
The screen on my X1 Carbon gave out after a couple months, and my loaner laptop in the meantime is an X240.
The worst thing about this laptop is how slowly the trackpoint moves with a default Ubuntu installation. However, it’s fixable:
cat /sys/devices/platform/i8042/serio1/serio2/speed
cat /sys/devices/platform/i8042/serio1/serio2/sensitivity
Note the starting values in case anything goes wrong, then fiddle around:
echo 255 | sudo tee /sys/devices/platform/i8042/serio1/serio2/sensitivity
echo 255 | sudo tee /sys/devices/platform/i8042/serio1/serio2/speed
Some binary search themed prodding and a lot of tee: /sys/devices/platform/i8042/serio1/serio2/sensitivity: Numerical result out of range has confirmed that both files accept values between 0-255. Interestingly, setting them to 0 does not seem to disable the trackpoint completely.
If you’re wondering why the configuration settings look like ordinary files but choke on values bigger or smaller than a short, go read about sysfs.
Folklore and fallacy
I was a student employee at the OSU Open Source Lab, on and off between internships and other jobs, for 4 years. Being part of the lab helped shape my life and career, in almost overwhelmingly positive ways. However, the farther I get from the lab the more clearly I notice how being part of it changed the way I form expectations about my own technical skills.
To show you the fallacy that I noticed myself falling into, I’d like to tell you a completely made-up story about some alphabetically named kangaroos. Below the fold, there’ll be pictures!
RustCamp videos are available
The videos from RustCamp are available here.
I asked Gankro what was up with the milkshake thing in his talk, and learned about this meme.
Don’t Starve
It was a lazy Sunday afternoon and I wanted to play Don’t Starve. This actually ended up meaning about 3 hours of intermittent troubleshooting and 1 hour of games, because Linux.
Get the files
I bought Don’t Starve from the Humble Bundle store, although there are other methods of obtaining it which strike a different balance between cost and convenience.
The downloaded file is dontstarve_x64_july21.tar.gz.
This Just Works
$ yaourt -S libcurl-compat
$ tar -xvf dontstarve_x64_july21.tar.gz
$ cd dontstarve/bin
$ LD_PRELOAD=libcurl.so.3 ./dontstarve
Below the fold is the troubleshooting process I went through to make it look so easy. Hopefully it’ll be of assistance to those searching for the errors that I ran into!
How many Rust channels are there?
I’m using search.mibbit.com to count these. All have at least one user in them as of 4pm PST 2015-07-31.
There are 53 Rust-related channels on irc.mozilla.org.
List below the fold.
Good times
People sometimes say “morning” or “evening” on IRC for a time zone unlike my own. Here’s a bash one-liner that emits the correct time-of-day generalization based on the datetime settings of the machine you run it on.
case $(($(date +%H)/6)) in 0|1)m="morning";;2)m="afternoon";;3)m="night";;esac; echo good $m
Printing
The office printers have instructions for setting them up under Windows, Mac, and Ubuntu. I had forgotten how to wrangle printers, since the last time I had to set up new ones was half a decade ago when I first joined the OSL.
Setting up printers on Arch is easy once you know the right incantations, but can waste some time if you try to do it by skimming the huge wiki page rather than either reading it thoroughly or just following these steps:
Install the CUPS client:
$ yaourt -S libcups
Add a magic line to /etc/cups/cups-files.conf:
SystemGroup username
With your username on the system, assuming you have root and will log in as yourself in the dialog it prompts for. That line can go anywhere in the file.
Make the daemon go:
$ sudo systemctl enable org.cups.cupsd.service
$ sudo systemctl start org.cups.cupsd.service
Visit the web interface at http://localhost:631.
Then you have a GUI sufficiently similar to the one in the instructions for Ubuntu!
There is no GUI client for CUPS to install. If you find yourself mucking about with gpr, xpp, kdeprint, or /etc/cups/client.conf, you have gone way too far down the wrong rabbit hole.
Outage postmortem: Replacing Rust Buildbot’s outdated cert
At the end of the day on July 14th, 2015, the certificate that Rust’s buildbot slaves were using to communicate with the buildmaster expired. This broke things. The problem started at midnight on July 15th, and was only fully resolved at the end of July 16th. Much of the reason for this outage’s duration was that I was learning about Buildbot as I went along.
Here’s how the outage got resolved, just in case anyone (especially future-me) finds themself Googling a similar problem.
Airport Wifi
Many “free” wifi hotspots give you a limited time per computer. If you’re traveling light and forgot to bring extra devices, it’s easy to give a Linux laptop multiple personalities:
$ ip link
1: lo
2: wlp4s0
3: enp0s25
$ ip link set dev wlp4s0 down
$ macchanger -r wlp4s0
$ ip link set dev wlp4s0 up
... And then connect to the wifi and jump through its silly captive portal hoops again!
Changing your MAC address occasionally can be part of a healthy security diet, making your device slightly more difficult to track, as well.
Interactive Rust Examples in Static Pages
Rust by Example has a little box where readers can interact with some example Rust code, run it using the playground, and see the results in the page. As a sysadmin I’m loath to recommend that anybody trust the playground for anything, but as a nerd and coder I recognize that it’s super cool and people want to use it.
There are 2 ways to stuff a Playground into your website: The easy way, and the “right” way. Here’s how to do it the easy way, and where to look for examples of the hard way.
Rust’s Packaging Status Across Distros
One of many questions facing the Rust infrastructure team right now is “What’s our packaging situation?”. We don’t have a centralized source of information on what version of Rust is available in which systems’ package managers, and we don’t even know where to find that information.
This post is the notes I’ve taken in researching Rust’s packaging status across distributions.
I last updated this post on 8/17/2015.
Mozilla Onboarding
On April 16th, I threw an application toward this job posting on careers.mozilla.org. I doubted whether I’d be qualified, but I reminded myself that most people apply to jobs where they meet only 80% of the critiera. I could, with some creative redefinition (“of course an internship at Intel is a year of relevant experience!”), meet every listed criterion. So I applied, since the worst they could say was no.
Here’s a rundown my experience getting interviewed and onboarded, which might be of interest to current Mozilla employees curious about how things have changed since they joined, and to anyone interested in working there.
One free ticket to Rust Camp
UPDATE: The ticket has been claimed by a local student! Thanks everyone for helping boost the signal about this.
How to find a Buildbot slave’s IP
Today I got a seemingly ordinary request from a community member who volunteers a build slave for Rust’s buildbot:
my builder is behind a firewall that just cycled IP's
and I don't know what it is
edunham: can you get the IP address of the bitrig builder for me?
I have admin access to the builders website but it doesn't list the IP addresses of builders
Moving a Jekyll site from GitHub Pages to Amazon S3
The rust-lang.org web site used to be hosted on GitHub Pages. This gave it excellent uptime and made deploying changes easy, but did not support HTTPS.
Downloading an S3 bucket
Since I’m curious about how often files are downloaded from S3, I enabled logging on the buckets serving them and directed the logs into a bucket which I created to hold them. Then I wanted to move everything on that logs bucket to my local machine, so I could poke around in the logs and ascertain the best way to turn them into useful information.
DMARC
Today, the security alias for a site I administer got an automated message pointing out that we lacked a DMARC record. Here’s what I learned about how to set up and test them.
Deleting spam logs
Some spammers got onto the Mozilla network, scraped a major channel’s user list, and PMed everybody requests to join their network from almost 1,000 different nicks. Here’s how I tidied up afterwards.
Installing Playpen on Ubuntu
One of the more egregious inconsistencies in Rust’s architecture is that play.rust-lang.org lives on an Arch box, while everything else is Ubuntu. Before the team has a dedicated operations person, the argument for using Arch was that playpen comes pre-packaged for it, whereas one has to build it oneself on Ubuntu.
But standardizing the infrastructure to one OS is a really cool thing to do, since it requires that much less thought and effort to do any update that affects every system (I’m looking at you, security patches).
Display Defaults
I’ve been running Arch on my work laptop and it’s pretty much working. However, I have a nice external monitor on my desk, and I keep having to manually configure the output to it with arandr. Here’s how I made it configure itself by default when X starts.
Playing with Ansible
Although I currently expect that I’ll end up choosing Salt for work, I’ve gotten nerdsniped by the apparent simplicity and power of Ansible. Since I’m trying to make a habit of narrating my first encounters with various tools, here’s a short novel of 0 through cloning a repo.
Configuration Management Comparison
Let’s just say that it’s pretty clear why my team at Mozilla decided to hire an operations specialist when they did. For the infrastructure which supports the Rust programming language, I get the relatively rare (compared to just hacking on an existing deployment) privilege of deploying configuration management from the ground up.
Recording Screencasts on Arch
Today I learned that there’s a trick to getting sound to work on Arch using recordmydesktop.
Oh, Windows...
I got a shiny new Thinkpad X1 Carbon 3rd Gen for my new job. It came with Windows pre-installed. Out of morbid curiosity and willingness to consider giving this shiny new allegedly-less-terrible Win8 thing a chance, I booted it up into the default Windows installation before wiping everything to install arch.
Open Infrastructure
My New Ops Job
Next week, I’m starting work as the only DevOps Engineer on the Mozilla Research team. While I’ve held a variety of superficially similar jobs in the past few years, this one offers a special opportunity to apply the values I appreciate as a software developer to the infrastructure design and maintenance which represents my work as an ops guy.